

一、Hadoop 到 Spark 的变化
Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后, 会将数据的运算结果从内存写入到磁盘中, 第二次 Mapredue 运算时在从磁盘中读取数据, 所以其瓶颈在 2 次运算间的多余 IO 消耗. Spark 则是将数据一直缓存在内存中, 直到计算得到最后的结果, 再将结果写入到磁盘, 所以多次运算的情况下, Spark 是比较快的. 其优化了迭代式工作负载
Hadoop 的局限 | Spark 的改进 |
|---|---|
抽象层次低,代码编写难以上手 | 通过使用 RDD 的统一抽象,实现数据处理逻辑的代码非常简洁 |
只提供了 Map 和 Reduce 两个操作,欠缺表达力 | 通过 RDD 提供了很多转换和动作,实现了很多基本操作,如 Sort, Join 等 |
一个 Job 只有 Map 和 Reduce 两个阶段,复杂的程序需要大量的 Job 来完成,且 Job 之间的依赖关系需要开发者自行管理 | 一个 Job 可以包含 RDD 的多个转换操作,在调度时可以生成多个阶段(Stage),而且如果多个 map 操作的 RDD 的分区不变,是可以放在同一个 Task 中进行 |
处理逻辑隐藏在代码细节中,缺乏整体逻辑视图 | RDD 的转换支持流式 API, 提供处理逻辑的整体视图 |
对迭代式数据处理性能比较差,Reduce 与下一步 Map 之间的中间结果只能存放在 HDFS 中 | 通过内存缓存数据,可大大提高迭代式计算的性能,内存不足时可以溢出到本地磁盘,而不是 HDFS |
ReduceTask 需要等待所有 MapTask 都完成后才可以开始 | 分区相同的转换构成流水线放在一个 Task 中运行,分区不同的转换需要 Shuffle,被划分到不同的 Stage 中,需要等待前面的 Stage 完成后才可以开始 |
时延高,只适用 Batch 数据处理,对于交互式数据处理和实时数据处理的支持不够 | 通过将流拆成小的 batch 提供 Discretized Stream 处理流数据 |
Spark 的主要特点还包括:
(1) 提供 Cache 机制来支持需要反复迭代计算或者多次数据共享, 减少数据读取的 IO 开销;
(2) 提供了一套支持 DAG 图的分布式并行计算的编程框架, 减少多次计算之间中间结果写到 Hdfs 的开销;
(3) 使用多线程池模型减少 Task 启动开稍, shuffle 过程中避免不必要的 sort 操作并减少磁盘 IO 操作。(Hadoop 的 Map 和 reduce 之间的 shuffle 需要 sort)
二、Spark 系统架构
明确相关术语
Application: Appliction 都是指用户编写的 Spark 应用程序,其中包括一个 Driver 功能的代码和分布在集群中多个节点上运行的 Executor 代码
Driver: Spark 中的 Driver 即运行上述 Application 的 main 函数并创建 SparkContext,创建 SparkContext 的目的是为了准备 Spark 应用程序的运行环境,在 Spark 中有 SparkContext 负责与 ClusterManager 通信,进行资源申请、任务的分配和监控等,当 Executor 部分运行完毕后,Driver 同时负责将 SparkContext 关闭,通常用 SparkContext 代表 Driver
Executor: 某个 Application 运行在 worker 节点上的一个进程, 该进程负责运行某些 Task, 并且负责将数据存到内存或磁盘上,每个 Application 都有各自独立的一批 Executor, 在 Spark on Yarn 模式下,其进程名称为 CoarseGrainedExecutor Backend。一个 CoarseGrainedExecutor Backend 有且仅有一个 Executor 对象, 负责将 Task 包装成 taskRunner, 并从线程池中抽取一个空闲线程运行 Task, 这个每一个 oarseGrainedExecutor Backend 能并行运行 Task 的数量取决与分配给它的 cpu 个数
Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型
Standalon : spark 原生的资源管理,由 Master 负责资源的分配
Apache Mesos: 与 hadoop MR 兼容性良好的一种资源调度框架
Hadoop Yarn: 主要是指 Yarn 中的 ResourceManager
Worker: 集群中任何可以运行 Application 代码的节点,在 Standalone 模式中指的是通过 slave 文件配置的 Worker 节点,在 Spark on Yarn 模式下就是 NoteManager 节点
Task: 被送到某个 Executor 上的工作单元,但 hadoopMR 中的 MapTask 和 ReduceTask 概念一样,是运行 Application 的基本单位,多个 Task 组成一个 Stage,而 Task 的调度和管理等是由 TaskScheduler 负责
Job: 包含多个 Task 组成的并行计算,往往由 Spark Action 触发生成, 一个 Application 中往往会产生多个 Job
Stage: 每个 Job 会被拆分成多组 Task, 作为一个 TaskSet, 其名称为 Stage,Stage 的划分和调度是有 DAGScheduler 来负责的,Stage 有非最终的 Stage(Shuffle Map Stage)和最终的 Stage(Result Stage)两种,Stage 的边界就是发生 shuffle 的地方
DAGScheduler: 根据 Job 构建基于 Stage 的 DAG(Directed Acyclic Graph 有向无环图 ),并提交 Stage 给 TASkScheduler。 其划分 Stage 的依据是 RDD 之间的依赖的关系找出开销最小的调度方法,如下图
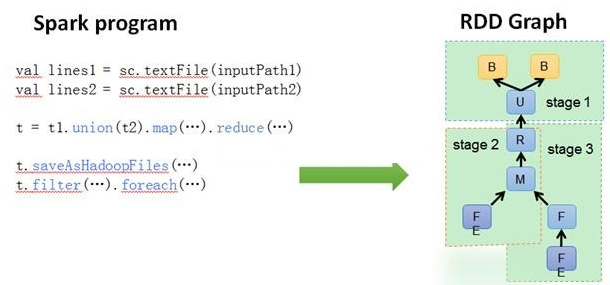
TASKSedulter: 将 TaskSET 提交给 worker 运行,每个 Executor 运行什么 Task 就是在此处分配的. TaskScheduler 维护所有 TaskSet,当 Executor 向 Driver 发生心跳时,TaskScheduler 会根据资源剩余情况分配相应的 Task。另外 TaskScheduler 还维护着所有 Task 的运行标签,重试失败的 Task。下图展示了 TaskScheduler 的作用
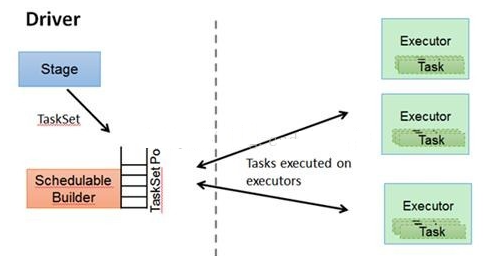
在不同运行模式中任务调度器具体为:
Spark on Standalone 模式为 TaskScheduler
YARN-Client 模式为 YarnClientClusterScheduler
YARN-Cluster 模式为 YarnClusterScheduler
将这些术语串起来的运行层次图如下:
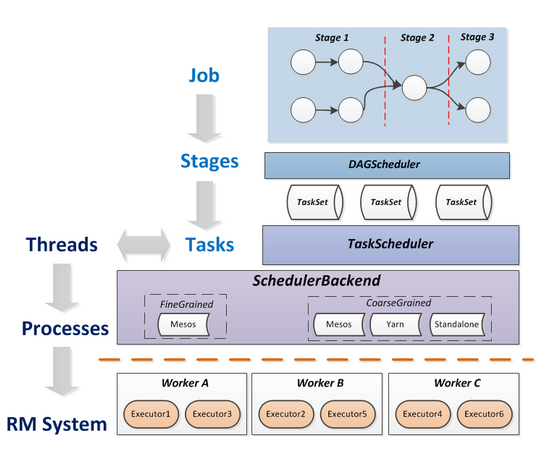
Job= 多个 stage,Stage= 多个同种 task, Task 分为 ShuffleMapTask 和 ResultTask,Dependency 分为 ShuffleDependency 和 NarrowDependency。
整个 Spark 集群中, 分为 Master 节点与 worker 节点,, 其中 Master 节点负责将串行任务变成可并行执行的任务集 Tasks, 同时还负责出错问题处理等, 而 Worker 节点负责执行任务. Driver 的功能是创建 SparkContext, 负责执行用户写的 Application 的 main 函数进程,Application 就是用户写的程序. 不同的模式可能会将 Driver 调度到不同的节点上执行.集群管理模式里, local 一般用于本地调试.每个 Worker 上存在一个或多个 Executor 进程, 该对象拥有一个线程池, 每个线程负责一个 Task 任务的执行. 根据 Executor 上 CPU-core 的数量, 其每个时间可以并行多个 跟 core 一样数量的 Task.Task 任务即为具体执行的 Spark 程序的任务.

spark 运行流程图如下:

构建 Spark Application 的运行环境,启动 SparkContext
SparkContext 向资源管理器(可以是 Standalone,Mesos,Yarn)申请运行 Executor 资源,并启动 StandaloneExecutorbackend,
Executor 向 SparkContext 申请 Task
SparkContext 将应用程序分发给 Executor
SparkContext 构建成 DAG 图,将 DAG 图分解成 Stage、将 Taskset 发送给 Task Scheduler,最后由 Task Scheduler 将 Task 发送给 Executor 运行
Task 在 Executor 上运行,运行完释放所有资源
Spark 运行特点:
每个 Application 获取专属的 executor 进程,该进程在 Application 期间一直驻留,并以多线程方式运行 Task。这种 Application 隔离机制是有优势的,无论是从调度角度看(每个 Driver 调度他自己的任务),还是从运行角度看(来自不同 Application 的 Task 运行在不同 JVM 中),当然这样意味着 Spark Application 不能跨应用程序共享数据,除非将数据写入外部存储系统
Spark 与资源管理器无关,只要能够获取 executor 进程,并能保持相互通信就可以了
提交 SparkContext 的 Client 应该靠近 Worker 节点(运行 Executor 的节点),最好是在同一个 Rack 里,因为 Spark Application 运行过程中 SparkContext 和 Executor 之间有大量的信息交换
Task 采用了数据本地性和推测执行的优化机制
三、Spark作业基本运行原理
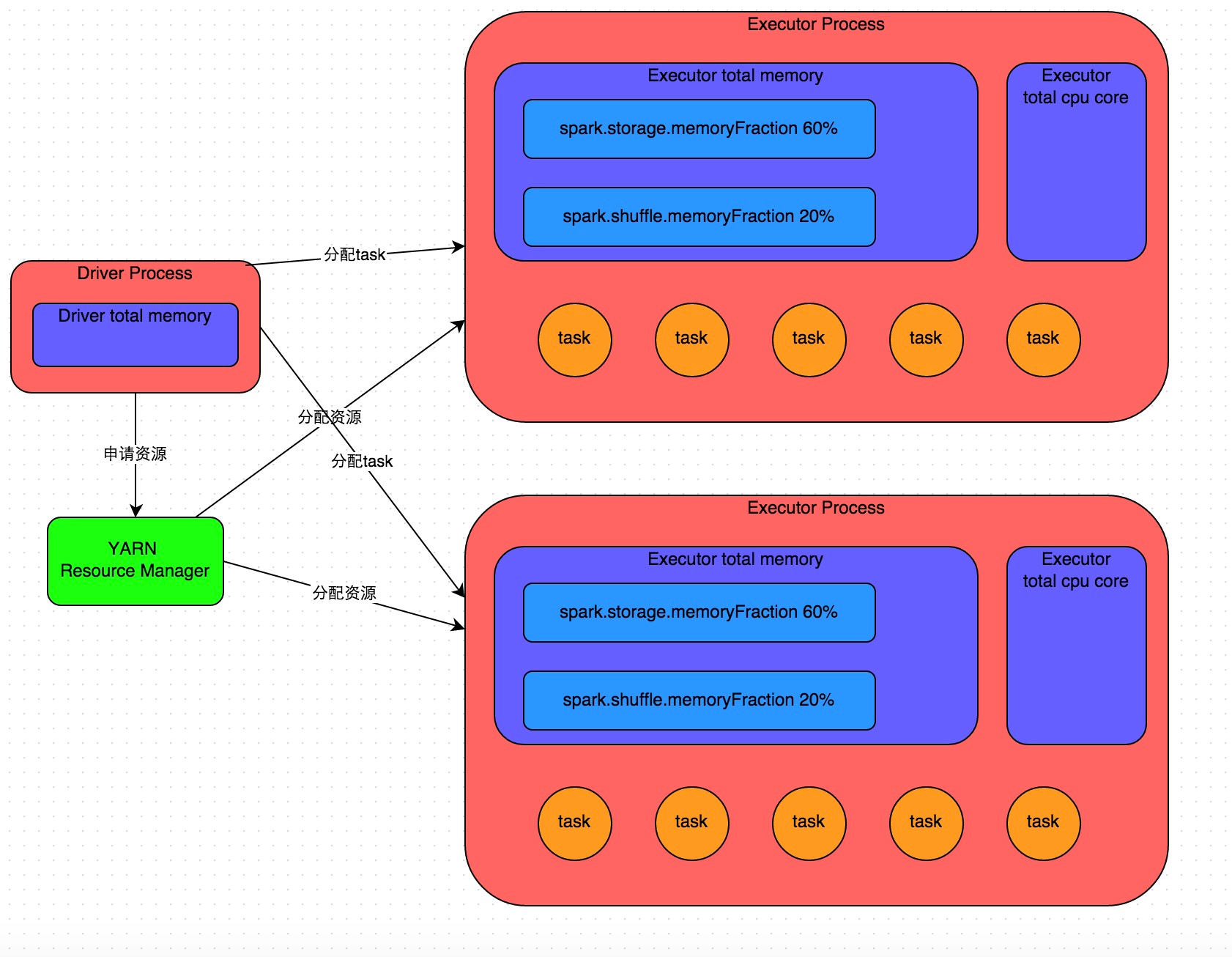
详细原理见上图。
我们使用 spark-submit 提交一个 Spark 作业之后,这个作业就会启动一个对应的 Driver 进程。根据你使用的部署模式(deploy-mode)不同,Driver 进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver 进程本身会根据我们设置的参数,占有一定数量的内存和 CPU core。而 Driver 进程要做的第一件事情,就是向集群管理器 (YARN 或者其他资源管理集群)申请运行 Spark 作业需要使用的资源,这里的资源指的就是 Executor 进程。YARN 集群管理器会根据我们为 Spark 作业设置的资源参数,在各个工作节点上,启动一定数量的 Executor 进程,每个 Executor 进程都占有一定数量的内存和 CPU core。
在申请到了作业执行所需的资源之后,Driver 进程就会开始调度和执行我们编写的作业代码了。Driver 进程会将我们编写的 Spark 作业代码分拆为多个 stage,每个 stage 执行一部分代码片段,并为每个 stage 创建一批 task,然后将这些 task 分配到各个 Executor 进程中执行。task 是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个 task 处理的数据不同而已。一个 stage 的所有 task 都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后 Driver 就会调度运行下一个 stage。下一个 stage 的 task 的输入数据就是上一个 stage 输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark 是根据 shuffle 类算子来进行 stage 的划分。如果我们的代码中执行了某个 shuffle 类算子(比如 reduceByKey、join 等),那么就会在该算子处,划分出一个 stage 界限来。可以大致理解为,shuffle 算子执行之前的代码会被划分为一个 stage,shuffle 算子执行以及之后的代码会被划分为下一个 stage。因此一个 stage 刚开始执行的时候,它的每个 task 可能都会从上一个 stage 的 task 所在的节点,去通过网络传输拉取需要自己处理的所有 key,然后对拉取到的所有相同的 key 使用我们自己编写的算子函数执行聚合操作(比如 reduceByKey() 算子接收的函数)。这个过程就是 shuffle。
当我们在代码中执行了 cache/persist 等持久化操作时,根据我们选择的持久化级别的不同,每个 task 计算出来的数据也会保存到 Executor 进程的内存或者所在节点的磁盘文件中。
因此 Executor 的内存主要分为三块:第一块是让 task 执行我们自己编写的代码时使用,默认是占 Executor 总内存的 20%;第二块是让 task 通过 shuffle 过程拉取了上一个 stage 的 task 的输出后,进行聚合等操作时使用,默认也是占 Executor 总内存的 20%;第三块是让 RDD 持久化时使用,默认占 Executor 总内存的 60%。
task 的执行速度是跟每个 Executor 进程的 CPU core 数量有直接关系的。一个 CPU core 同一时间只能执行一个线程。而每个 Executor 进程上分配到的多个 task,都是以每个 task 一条线程的方式,多线程并发运行的。如果 CPU core 数量比较充足,而且分配到的 task 数量比较合理,那么通常来说,可以比较快速和高效地执行完这些 task 线程。
文章引用自:tony~ 博客小屋
