Data·Stack
首页
门类
默认分类
大数据
JAVA
PYTHON
晋级之路-数据结构·算法
千变工作-BI
LangChain
大模型
埃利斯-踏足社会
咻咻
抖音热榜
关于
切换主题
登录
数据ETL-Apache Flume详解
2025-03-16
180
0
ETL
Kafka副本同步策略(ISR)
2024-01-18
443
0
Kafka
Hadoop和Spark的联系
2023-12-29
146
0
Spark
Scala
Flink中的多事件Join
2023-12-28
264
0
Flink
Hive-数据模型
2023-10-11
223
0
Hive
hive基础-知识必备
2023-10-11
245
0
Hive
数据仓库
Spark基础-基础必备
2023-10-09
164
0
Spark
Hadoop基础-知识必备
2023-10-06
152
0
Hadoop
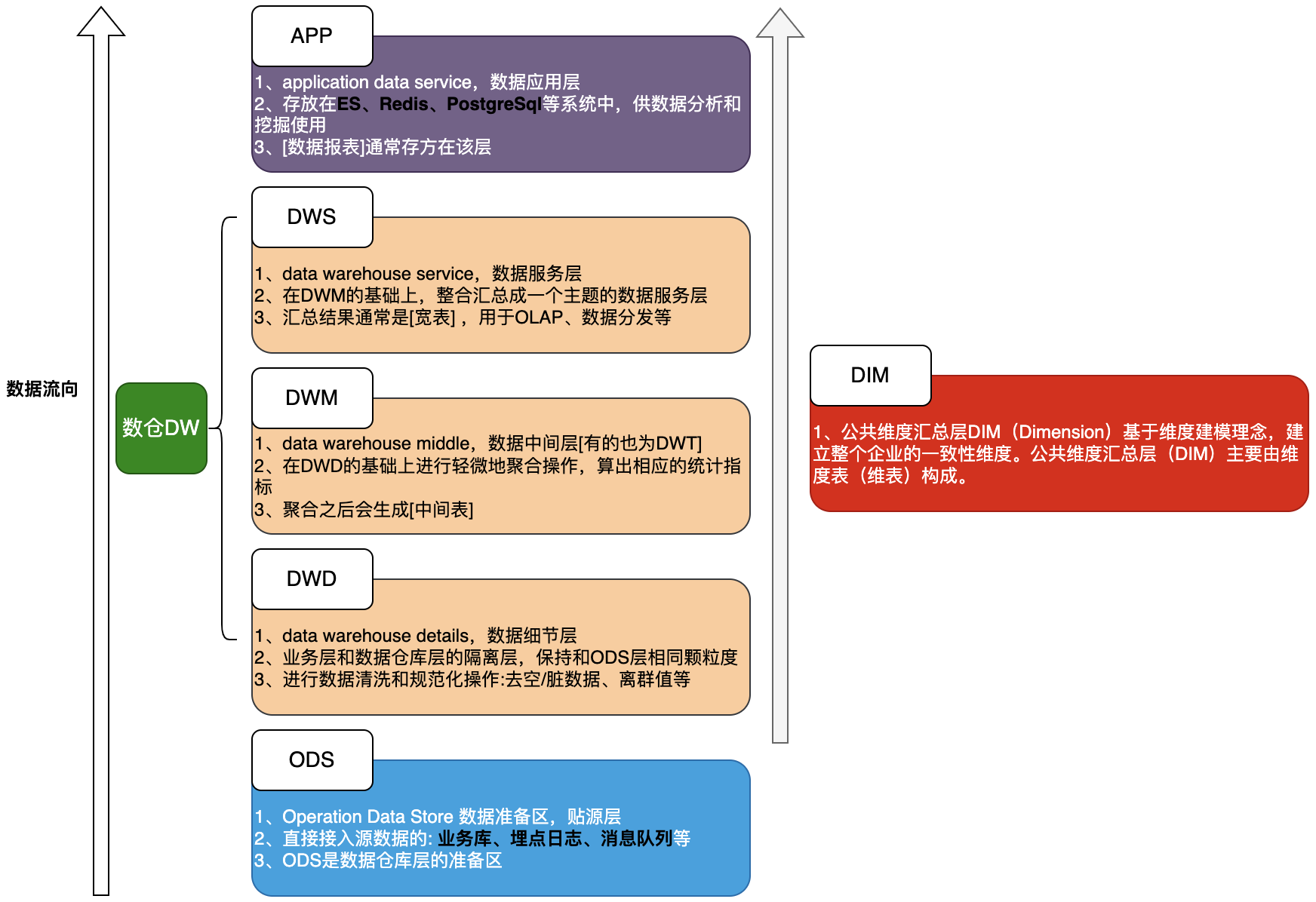
数据仓库体系内容梳理
2023-10-04
583
0
数据仓库
Hive