

1、Hive中Map和Reduce
Map 阶段:
1. 对文件进行逻辑切片 split,默认大小为 hdfs 块大小,每一块对应一个 mapTask;
2. 对切片中的数据按行读取,解析返回 <K,V> 形式,key 为每一行的偏移量,value 为每一行的数据;
3. 调用 map 方法处理数据,读取一行调用一次;
4. 对 map 方法计算的数据进行分区 partition,排序 sort; 默认不分区,因为只有一个 reduceTask 处理数据,分区数 =reduceTask 数,计算规则:key 的 hash 值对 reduce 取模,保证相同 key 一定在同一分区;
5.map 输出数据一同写入到数据缓冲区,达到一定的条件溢写到磁盘;
6.spill 溢出的文件进行 combiner 规约,combiner 为 map 阶段的 reduce,并不是每个 mapTask 都有该流程,对于 combine 需要慎用,例如:求平均数,如果提前 combine 则会导致最终的计算结果不一致;
7. 对所有溢出的文件(分区且有序)进行最终 merge 合并,成为一个大文件;
Reduce 阶段:
1. 从 MapTask 复制拉取其对应的分区文件;
2. 将 copy 的数据进行 merge 合并,再对合并后的数据排序,默认按照 key 字典序排序;
3. 对排序后的数据调用 reduce 方法;
2、Hive执行流程
1.Client 将查询语句发送给 Driver;
2.Driver 调用解析器对 query 解析成抽象语法树,发送给编译器;
3. 编译器拿到抽象语法树,向元数据库请求获取对应的元数据信息;
4. 元数据库接收请求并返回元数据信息;
5. 编辑器根据元数据生成逻辑执行计划,返回给 Driver;
6.Driver 调用优化器对逻辑执行计划进行优化,发送给执行器;
7. 执行器将优化好的逻辑执行计划转化成可运行的 Job,并发送给 Hadoop;
8.Driver 对执行结果进行回收;
3、数据质量衡量标准
1). 数据准确性 2). 数据精确性 3). 数据真实性 4). 数据及时性 5). 数据即时性 6). 数据完整性 7). 数据全面性 8). 数据的关联性
4、数据质量保证
1). 从技术层面说,需要一套高效、健壮的 ETL 流程,以保证数据清洗、转换后的正确性和一致性;
2). 从流程上来说,整个任务是由多个子任务组成,按照既定步骤执行完成,后置依赖前置,整个流程需要自动化,并且那个流程出现问题需要及时预警,通知相关人员及时处理;
3). 从管理层面上来说,数据仓库是构建在公司各个业务系统之上,它是一面镜子,很多时候它能反映出业务系统的问题,所以需要管理层的支持和约束,比如通过第一条说的事后自动检验机制反映出业务系统的维护错误,需要相应的业务系统维护人员及时处理;
5、元数据的类型
根据用途的不同,可将元数据分为两类:技术元数据( Technical Metadata) 和业务元数据( Business Metadata )。
1.1 技术元数据
技术元数据是存储关于数据仓库系统技术细节的数据,是用于开发、管理和维护数据仓库使用的数据。
它主要包含以下信息:
数据仓库结构的描述,包括仓库模式、视图、维、层次结构和导出数据的定义,以及数据集市的位置和内容;
业务系统、数据仓库和数据集市的体系结构和模式;
汇总用的算法,包括度量和维定义算法,数据粒度、主题领域、聚合、汇总和预定义的查询与报告;
由操作环境到数据仓库环境的映射,包括源数据和它们的内容、数据分割、数据提取、清理、转换规则和数据刷新规则及安全(用户授权和存取控制)。
1.2 业务元数据
业务元数据从业务角度描述了数据仓库中的数据,它提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员也能够“读懂”数据仓库中的数据。 业务元数据主要包括以下信息: 使用者的业务术语所表达的数据模型、对象名和属性名; 访问数据的原则和数据的来源; 系统所提供的分析方法及公式和报表的信息。
6、hive小文件处理方案(博客)[https://blog.csdn.net/qq_20042935/article/details/123110437]
方式一:对已有的数据进行定时或实时的小文件合并
方式二:在生成小文件前,进行相关的配置合并来预防
方式三:使用 HAR 归档文件
7、事实表设计8大原则
1). 尽可能包含所有与业务过程相关的事实
2). 只选择与业务过程相关的事实
3). 在选择维度和事实前必须先声明粒度
4). 分解不可加性为可加性
5). 事实表中单位必须保持一致
6). 特殊值做处理
7). 同一个事实表内不能存在多种粒度事实
8). 使用退化为度提高事实表易用性
8、维度表设计原则
1). 维度属性尽量丰富,为数据使用打下基础; 2). 给出详实的,具有真实意义的描述; 3). 区分数值型属性和维度; 4). 沉淀出通用的维度属性,为一致性维度做准备; 5). 退化维度; 6). 缓慢变化维度;
9、数据架构评价标准
响应速度:数据架构的主要场景包括:业务开发、数据产品、运营分析三大类,不论是那种场景,数据架构均应该在尽可能短的时间内响应需求;
可复用性:只有复用能力上来了,响应速度才能提上来,体现在下游依赖、调用次数、核心字段覆盖率等指标上;
稳定性:除了日常任务不出问题以外,一旦发现了问题,能在多短的时间内定位和恢复问题,就非常重要;
健壮性:除了电商等已经耕耘多年的领域外,绝大多数业务模型,都会快速的变化,如何适应这种变化,就非常考验架构功底。
10、left semi join 和 left join
left semi join 特点:
1.left semi join join 子句中右边的表只能在 on 子句中设置过滤条件
2.left semi join 中最后 select 的结果只许出现左表。
3. 因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而 join 则会一直遍历。
11、hive执行计划
执行计划分为两部分:
stage 依赖 (STAGE DEPENDENCIES)
这部分展示本次查询分为两个 stage:Stage-1,Stage-0.
一般 Stage-0 是最终给查询用户展示数据用的,如 LIMITE 操作就会在这部分。
Stage-1 是 mr 程序的执行阶段。
stage 详细执行计划 (STAGE PLANS)
包含了整个查询所有 Stage 的大部分处理过程。
特定优化是否生效,主要通过此部分内容查看。
12、hive文件格式
TextFile: 默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合 Gzip、Bzip2 使用,但使用 Gzip 这种方式,hive 不会对数据进行切分,从而无法对数据进行并行操作。
SequenceFile: SequenceFile 是 Hadoop API 提供的一种二进制文件,它将数据以 <key,value> 的形式序列化到文件中。这种二进制文件内部使用 Hadoop 的标准的 Writable 接口实现序列化和反序列化。它与 Hadoop API 中的 MapFile 是互相兼容的。Hive 中的 SequenceFile 继承自 Hadoop API 的 SequenceFile,不过它的 key 为空,使用 value 存放实际的值, 这样是为了避免 MR 在运行 map 阶段的排序过程。
RCFile: RCFile 是 Hive 推出的一种专门面向列的数据格式。 它遵循“先按列划分,再垂直划分”的设计理念。当查询过程中,针对它并不关心的列时,它会在 IO 上跳过这些列。需要说明的是,RCFile 在 map 阶段从 远端拷贝仍然是拷贝整个数据块,并且拷贝到本地目录后 RCFile 并不是真正直接跳过不需要的列,并跳到需要读取的列, 而是通过扫描每一个 row group 的头部定义来实现的,但是在整个 HDFS Block 级别的头部并没有定义每个列从哪个 row group 起始到哪个 row group 结束。所以在读取所有列的情况下,RCFile 的性能反而没有 SequenceFile 高。
ORCfile: ORC 是列式存储,有多种文件压缩方式,并且有着很高的压缩比。文件是可切分 (Split) 的。因此,在 Hive 中使用 ORC 作为表的文件存储格式,不仅节省 HDFS 存储资源, 查询任务的输入数据量减少,使用的 MapTask 也就减少了。提供了多种索引,row group index、bloom filter index。ORC 可以支持复杂的数据结构(比如 Map 等)
13、sql转mapreduce过程
HQL 转换成 MapReduce 的执行计划包括如下几个步骤: HiveSQL ->AST(抽象语法树) -> QB(查询块) ->OperatorTree(操作树)-> 优化后的操作树 ->mapreduce 任务树 -> 优化后的 mapreduce 任务树
分步骤:
1.SQL Parser:Antlr 定义 SQL 的语法规则,完成 SQL 语法解析,将 SQL 转化为抽象语法树 AST Tree;
2.Semantic Analyzer:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
3.Logical plan:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
4.Logical plan optimizer: 逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少 shuffle 数据量;
5.Physical plan:遍历 OperatorTree,翻译为 MapReduce 任务;
6.Logical plan optimizer:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划;
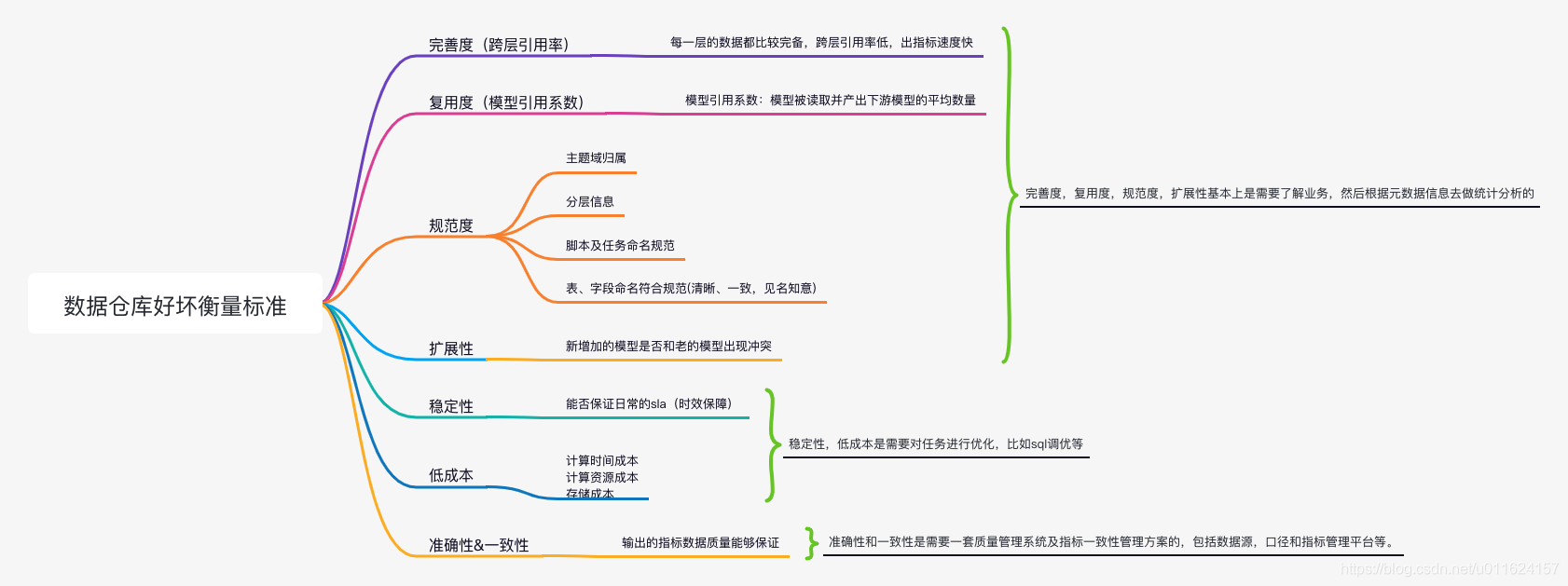
14、如何评价一个数仓模型的好坏
15、如何判定一个job的map和reduce的数量
map 数量:
splitSize=max{minSi***{maxSize,blockSize}}
map 数量由处理的数据分成的 block 数量决定 default_num = total_size / split_size;
reduce 数量:
reduce 的数量 job.setNumReduceTasks(x);x 为 reduce 的数量。不设置的话默认为 1。
16、map和reduce个数怎么确定
Map 数量设置:
默认:如果不设置其他参数,默认按照输入的文件数决定 Map 的数量。
通过合并文件数:在不确定 HDFS 内文件情况下 (小文件),可以通过设置小文件合并的方式来达到控制 Map 数。
输入合并小文件设置:
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; #执行Map前进行小文件合并
set mapred.max.split.size=128000000; #每个Map最大输入大小,单位为KB
set mapred.min.split.size.per.node=100000000; #一个节点上split的至少的大小,单位为KB
set mapred.min.split.size.per.rack=100000000; #一个交换机下split的至少的大小,单位为KB输出合并小文件设置:
set hive.merge.mapfiles = true #在Map-only的任务结束时合并小文件
set hive.merge.mapredfiles = true #在Map-Reduce的任务结束时合并小文件
set hive.merge.sparkfiles = true #在hive on spark任务后开启合并小文件
set hive.merge.size.per.task = 256*1000*1000 #合并文件的大小
set hive.merge.smallfiles.avgsize=16000000 #当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge通过参数设置 Map 数:
1. 通过设置文件切分以控制 Map 数量:mapred.min.split.size 在客户端进行设置
2. 参数:mapred.map.tasks,当然这个参数需要达到一定条件才能生效,只有当 InputFormat 决定了 map 任务的个数比mapred.map.tasks值小时才起作用
3. 还可以通过 JobConf 的conf.setNumMapTasks(int num)设置 map 数量
Reduce 数量设置:
在不指定 reduce 个数情况下,hive 会基于参数hive.exec.reducers.bytes.per.reducer和hive.exec.reducers.max来控制 reduce 数量,总数不会超过参数hive.exec.reducers.max设置的值,当然也可以通过参数mapreduce.job.reduces硬性规定 reduce 数量。 也可以通过 conf.setNumReduceTasks(int num) 设置。
17、Maptask的个数由什么决定
一个 job 的 map 阶段 MapTask 并行度(个数),由客户端提交 job 时的切片个数决定。
18、Hive数据倾斜及处理
数据倾斜产生的原因?
1.key 分布不均匀; 2. 业务数据本身的特性; 3. 建表时考虑不周; 4. 某些 SQL 语句本身就有数据倾斜;
数据倾斜的处理
1)先 group by 再 count 代替 count(distinct)。COUNT DISTINCT 操作只有一个 Reduce Task,数据量大时会导致整个 Job 很难完成。
2) 采用 Map Join。
3) 开启数据倾斜时的负载均衡:set hive.groupby.skewindata=true。当选项设定为 true,生成的查询计划会有两个 MR Job:
1. 第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;
2. 第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的原始 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
4) 空 KEY 过滤:对于异常值如果不需要的话,最好是提前在 where 条件里过滤掉,这样可以使计算量大大减少。
5) 控制空值分布:将为空的 key 转变为字符串加随机数或纯随机数,将因空值而造成倾斜的数据分不到多个 Reducer。
19、主题域划分
按照业务或业务过程划分:比如一个靠销售广告位置的门户网站主题域可能会有广告域,客户域等,而广告域可能就会有广告的库存,销售分析、内部投放分析等主题;
根据需求方划分:比如需求方为财务部,就可以设定对应的财务主题域,而财务主题域里面可能就会有员工工资分析,投资回报比分析等主题;
按照功能或应用划分:比如微信中的朋友圈数据域、群聊数据域等,而朋友圈数据域可能就会有用户动态信息主题、广告主题等;
按照部门划分:比如可能会有运营域、技术域等,运营域中可能会有工资支出分析、活动宣传效果分析等主题;
20、维度建模过程
业务过程选择
在业务系统中,如果业务表过多,挑选我们感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。
声明粒度
1. 数据粒度指数据仓库中保存数据的细化程度; 2. 声明粒度意味着精确定义事实表中的一行数据表示什么, 尽可能地选择最小粒度满足各种各样的需求;3. 典型的业务过程如下: 订单中的每个酒店项作为下单事实表的一行,粒度为每次;
确定维度
维度的主要作用是描述业务是事实。主要表示的是 "谁、何时、何地" 的信息;
确定事实
1. 事实指的是业务中的度量值。例如订单金额、下单次数;2. 根据维度建模中星型模型思想,将维度进行退化。将地区表和省份表退化为地区维度表,活动信息表和活动规则表退化为活动维度表,将商品表、品类表、spu 表、商品三级品类、商品二级品类、商品一级品类退化为商品维度表;
21、PB及大数据处理,比如join优化
在这里我默认为是大表 join 大表场景来提出优化方案:
方案一: 实际上此思路有两种途径:限制行和限制列
限制行的思路是不需要 join B 全表,而只需要 join 其在 A 表中存在的,对于本问题场景,就是过滤掉不需要的数据。
限制列的思路是只取需要的字段,加上如上的限制后,检查过滤后的 B 表是否满足了 Hive mapjoin 的条件,如果能满足,那么添加过滤条件生成一个临时 B 表,然后 mapjoin 该表即可。
方案二: join 时用 case when 语句
此种解决方案应用场景是:倾斜的值是明确的而且数量很少,比如 null 值引起的倾斜。其核心是将这些引起倾斜的值随机分发到 Reduce, 其主要核心逻辑在于 join 时对这些特殊值 concat 随机数,从而达到随机分发的目的。
方案三:
1. 通用方案
此方案的思路是建立一个 numbers 表,其值只有一列 int 行,比如从 1 到 10(具体值可根据倾斜程度确定),然后放大 B 表 10 倍,再取模 join。 此思路的核心在于,既然按照列分发会倾斜,那么再人工增加一列进行分发,这样之前倾斜的值的倾斜程度会减少到原来的 1/10,可以通过配置 numbers 表改放大倍数来降低倾斜程度,但这样做的一个弊端是 B 表也会膨胀 N 倍。
2. 专用方案
通用方案的思路把 B 表的每条数据都放大了相同的倍数,实际上这是不需要的,只需要把大卖家放大倍数即可:需要首先知道大卖家的名单,即先建立一个临时表动态存放每天最新的大卖家(比如 dim_big_seller), 同时此表的大卖家要膨胀预先设定的倍数(1000 倍)。在 A 表和 B 表分别新建一个 join 列,其逻辑为:如果是大卖家,那么 concat 一个随机分配正整数(0 到预定义的倍数之间,本例为 0~1000);如果不是,保持不变。
方案四: 动态一分为二
实际上方案 2 和 3 都用了一分为二的思想,但是都不彻底,对于 mapjoin 不能解决的问题,终极解决方案是动态一分为二,即对倾斜的键值和不倾斜的键值分开处理,不倾斜的正常 join 即可,倾斜的把他们找出来做 mapjoin,最后 union all 其结果即可。但是此种解决方案比较麻烦,代码复杂而且需要一个临时表存放倾斜的键值。
22、hive的各种join及特点(join优化)
common join:如果未设置 mapjoin 或通过检测不符合 mapjoin 时转换为 common join,即在 reduce 阶段完成 join,整个过程包含 map、shuffle、reduce,
map join:大小表 join 优化,可以通过参数
--默认值为true,自动开户MAPJOIN优化 set hive.auto.convert.join=true; --默认值为2500000(25M),通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中 set hive.mapjoin.smalltable.filesize=2500000; 来开启和指定小表大小,当然也可以通过标识/*STREAMTABLE(a)*/来标识大表。bucket-mapjoin:用于中型表和大表关联,通过参数开启,前提表是桶表
set hive.optimize.bucketmapjoin = true; --一个表的bucket数是另一个表bucket数的整数倍 --列 == join列 --必须是应用在map join的场景中 --注意:如果表不是bucket的,则只是做普通join。smb join:用于优化大表与大表 join,smb 是 sort merge bucket 操作是 Bucket-MapJoin 的优化,首先进行排序,继而合并,然后放到所对应的 bucket 中。
--写入数据强制分桶 set hive.enforce.bucketing=true; --写入数据强制排序 set hive.enforce.sorting=true; --开启bucketmapjoin set hive.optimize.bucketmapjoin = true; --开启SMB Join set hive.auto.convert.sortmerge.join=true; set hive.auto.convert.sortmerge.join.noconditionaltask=true; --小表的bucket数=大表bucket数 --Bucket 列 == Join 列 == sort 列 --必须是应用在bucket mapjoin 的场景中left semi join(代替 in): LEFT SEMI JOIN 本质上就是 IN/EXISTS 子查询的表现,是 IN 的一种优化。 LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方都不行。 因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,join 会产生多条。 left semi join 是只传递表的 join key 给 map 阶段,因此 left semi join 中最后 select 的结果只许出现左表。因为右表只有 join key 参与关联计算了。
left anti join(代替 not in): LEFT ANTI JOIN 本质上就是 NOT IN/EXISTS 子查询的表现,是 NOT IN 的一种优化。 当 on 条件不成立时,才返回左表中的数据,保留在结果集中。
23、算子解释
主要区别
ReduceByKey 没有初始值 分区内和分区间逻辑相同
foldByKey 有初始值 分区内和分区间逻辑相同
aggregateByKey 有初始值 分区内和分区间逻辑可以不同
combineByKey 初始值可以变化结构 分区内和分区间逻辑不同
算子解释
combineByKey:最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。 combineByKey: 方法需要三个参数 第一个参数表示:将相同 key 的第一个数据进行结构的转换,实现操作 第二个参数表示:分区内的计算规则 第三个参数表示:分区间的计算规则。
foldByKey:当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey
aggregateByKey:aggregateByKey 是将数据根据不同的规则分别进行不同的分区内计算和分区间计算,规则分别设立
aggregateByKey 的返回值和初始化值必须相同
aggregateByKey 算子是函数柯里化,存在两个参数列表:
第一个参数列表中的参数表示初始值
第二个参数列表中含有两个参数
2.1 第一个参数表示分区内的计算规则
2.2 第二个参数表示分区间的计算规则
groupByKey:将数据源的数据根据 key 对 value 进行分组,形成一个对偶元组,元组的第二个元素是 value,groupBy 分组后的元组第二个元素是 KV。
reduceByKey:将数据按照相同的 Key 对 Value 进行聚合
partitionBy:将数据按照指定 Partitioner 重新进行分区。隐式转换为 PairRDDFunctions,二次编译。 区别于 coalease
repartition:是数量上的改变,二 partitionBy 是功能上的改变。
subtract:前一个 RDD 元素为主,去除两个 RDD 中重复元素,将其他元素保留下来
union:对原 RDD 和参数 RDD 求并集后返回一个新的 RDD,要求类型相同
intersection:对源 RDD 和参数 RDD 求交集后返回一个新的 RDD,要求类型相同
repartition:该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。对于分区数多少的 RDD 都可以转换,因为无论如何都会经 shuffle 过程。
coalesce:根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率。spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本 coalesce 方法默认不会打乱分区重新组合,容易导致数据倾斜 但 coalease 还有第二个参数,默认为 false,不 shuffle,设置为 true 即可进行 shuffle 让数据变的均衡。
glom:将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
flatMap:将处理的数据进行扁平化后再进行映射处理
mapPartitionsWithIndex:将待处理的数据以分区为单位发送到计算节点进行处理
mapPartitions: map 和 mapPartition 的区别:map 算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。是串行,效率低 。mapPartitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变,所以可以增加或减少数据。并行,效率高,但消耗内存,容易造成内存溢出。
24、distinct和group by解释
默认情况下,distinct 会被 hive 翻译成一个全局唯一 reducer 来做去重操作,此时并行度为 1。
而 group by 则会被解析成分组聚合运算,会有多个 reducer 任务并行处理,每个 reducer 会得到部分数据,进行分组聚合。
高版本 hive 官方应该是一件优化了 distinct。
25、union和union all的区别
union:对两个结果进行并集操作,不包括重复行,默认会进行去重。
union all:对两个结果进行并集操作,包括重复行,不进行排序。
26、Hive优化
SQL 优化
1. 尽可能地减少处理数据量;
2.group by 代替 distinct;
3. 使用 Explain 查看 sql 的执行计划,查看拖慢效率内容,针对性做调整(比如某个表数据量大,消耗资源多);
4. 禁止使用『%』前导的查询;
5. 用 union 代替 or;
6.null 值判断、!= 或 <> 操作符会导致全表扫描;
7. 用 between、exists 代替 in,用 not exists 代替 not in;
8. 多使用 limit;
Join 优化
大小表:正常使用 join 函数,其中 map join 会自动优化,也可以使用 stream join() 指定大表
大表和大表关联:需要注意是否存在数据倾斜的问题。主要关注空值或无意义值、热点数据、长尾数据。避免产生笛卡尔积。
数据倾斜的优
空值或无意义值:过滤掉
热点或长尾
可以单独处理倾斜的 key,是处理空值方法的拓展,不过倾斜的 key 变成了有意义的。
一般来讲倾斜的 key 都很少,可以抽样出来,拼一个较小的随机数,再进行聚合。存入临时表或者直接 union 起来。
Mapreduce 的优化
map 数
map 数过大:map 阶段输出文件太小,产生大量小文件。初始化和创建 map 的开销大。
map 数过小:文件处理或查询并发度小,job 执行空间过长。大作业时,容易堵塞集群。
reduce 数
ruduce 数过大:生成了很多个小文件,那么如果这些小文件作为下一个 job 输入,则也会出现小文件过多需要进行合并(消耗资源)的问题。启动和初始化 reduce 也会消耗大量的时间和资源,有多少个 reduce 就会有多少个输出文件。
reduce 数过小:每个文件很大,执行耗时。可能出现数据倾斜
27、拉链表
拉链表
1)简单来说就是历史表(记录一个事物从开始,直到当前,所有状态的变化的信息)
2)拉链表属于维度表
拉链表的结构
拉链表中一行数据,就是一个状态,而列有 2 个很特殊的字段,开始日期和结束日期
拉链表适用场景
数据变化的比例和频率不是很大,俗称缓慢变化维
28、spark的执行速度是优于hive的,从源码或架构上说明为什么?
Apache Spark 的执行速度通常被认为优于 Apache Hive,这主要得益于其独特的架构和设计理念。以下是一些关键点,从源码和架构层面解释了为什么 Spark 在执行速度上优于 Hive:
1. 内存计算(In-Memory Processing):
- Spark 采用内存计算,意味着数据在处理时主要存储在 RAM 中,而不是磁盘上。这减少了数据读写的时间,尤其是在处理大数据集时。
- 相比之下,Hive 主要基于磁盘的计算,这意味着更多的磁盘 I/O 操作,从而导致性能下降。
2. 优化的执行引擎(Optimized Execution Engine):
- Spark 的执行引擎针对多种数据源进行了优化,包括 HDFS、Cassandra、HBase 等,能够更高效地处理大数据。
- Hive 则主要是为 Hadoop 设计,专注于批处理,其执行引擎没有针对快速数据处理进行优化。
3. 高级 API 和数据结构(Advanced APIs and Data Structures):
- Spark 提供了如 RDD(弹性分布式数据集)和 DataFrame 这样的高级数据结构,使得数据处理更加高效和易于编程。
- Hive 使用较传统的 MapReduce 作为其底层处理机制,这使得数据处理效率相对较低。
4. DAG 执行计划(DAG Execution Plan):
- Spark 使用 DAG(有向无环图)来优化任务的执行计划。它能够智能地将多个操作合并在一个阶段内完成,减少了数据的移动和 I/O 操作。
- Hive 传统上依赖于 MapReduce,每个任务分为 Map 和 Reduce 两个阶段,通常会导致更多的数据读写和网络通信。
5. 动态资源管理(Dynamic Resource Allocation):
- Spark 支持动态资源管理,可以根据实际工作负载动态调整资源分配,提高资源利用率。
- Hive 的资源管理相对静态,不容易根据实时负载调整资源。
6. 实时处理能力(Real-Time Processing Capability):
- Spark 支持实时数据处理(例如 Spark Streaming),适用于需要快速响应的场景。
- Hive 主要面向批处理,对实时数据处理的支持较弱。
7. 优化的查询执行计划(Optimized Query Execution Plans):
- Spark SQL 使用高级的查询优化技术,如 Catalyst 优化器,提供高效的查询执行。
- HiveQL,虽然也进行了优化,但其查询优化能力通常不如 Spark SQL。
总结来说,Spark 之所以在执行速度上优于 Hive,主要归功于其内存计算机制、优化的执行引擎、高级 API、DAG 执行计划、动态资源管理、实时处理能力以及优化的查询执行计划。这些特点使 Spark 在处理大规模数据集时,尤其是需要快速迭代和实时分析的场景中,表现出更高的效率和灵活性。
