

1、Spark宽窄依赖
窄依赖 (Narrow Dependency): 指父 RDD 的每个分区只被子 RDD 的一个分区所使用。例如 map、filter 等这些算子的一个 RDD,对它的父 RDD 只有简单的一对一的关系,RDD 的每个 partition 仅仅依赖于父 RDD 中的一个 partition,父 RDD 和子 RDD 的 partition 之间的对应关系,是一对一的。
宽依赖 (Shuffle Dependency): 父 RDD 的每个分区都可能被子 RDD 的多个分区使用,例如 groupByKey、 reduceByKey,sortBykey 等算子,这些算子其实都会产生 shuffle 操作,每一个父 RDD 的 partition 中的数据都可能会传输一部分到下一个 RDD 的每个 partition 中。此时就会出现,父 RDD 和子 RDD 的 partition 之间,具有错综复杂的关系,这种情况就叫做两个 RDD 之间是宽依赖,同时,他们之间会发生 shuffle 操作。
2、Map、FlatMap、MapPartation的区别
1.Map:map 方法返回的是一个 object,map 将流中的当前元素替换为此返回值,map 是对 rdd 中的每一个元素进行操作;
2.FlatMap:flatMap 方法返回的是一个 Stream,FlatMap 将流中的当前元素替换为此返回流拆解的流元素;
3.MapPartitions 则是对 rdd 中的每个分区的迭代器进行操作;
MapPartitions 的优点:
如果是普通的 Map,比如一个 Partition 中有 1 万条数据。ok,那么你的 Function 要执行和计算 1 万次。
使用 MapPartitions 操作之后,一个 Task 仅仅会执行一次 Function,Function 一次接收所有的 partition 数据。只要执行一次就可以了,性能比较高。如果在 Map 过程中需要频繁创建额外的对象 (例如将 rdd 中的数据通过 jdbc 写入数据库,Map 需要为每个元素创建一个链接而 MapPartition 为每个 Partition 创建一个链接), 则 MapPartitions 效率比 Map 高的多。
SparkSql 或 DataFrame 默认会对程序进行 mapPartition 的优化。
MapPartitions 的缺点:
如果是普通的 Map 操作,一次 Function 的执行就处理一条数据;那么如果内存不够用的情况下, 比如处理了 1 千条数据了,那么这个时候内存不够了,那么就可以将已经处理完的 1 千条数据从内存里面垃圾回收掉,或者用其他方法,腾出空间来吧。所以说普通的 map 操作通常不会导致内存的 OOM 异常。
但是 MapPartitions 操作,对于大量数据来说,比如甚至一个 Partition,100 万数据,一次传入一个 Function 以后,那么可能一下子内存不够,但是又没有办法去腾出内存空间来,可能就 OOM,内存溢出。
3、Rdd、DataFrame、DataSet的区别
明细概述
1. 细说 DataFrame
DataFrame 的前身是 SchemaRDD。Spark1.3 更名为 DataFrame。不继承 RDD,自己实现了 RDD 的大部分功能。与 RDD 类似,DataFrame 也是一个分布式数据集:
1)DataFrame 可以看做分布式 Row 对象的集合,提供了由列组成的详细模式信息,使其可以得到优化。DataFrame 不仅有比 RDD 更多的算子,还可以进行执行计划的优化。
2)DataFrame 更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即 schema。
3)DataFrame 也支持嵌套数据类型(struct、array 和 map)。
4)DataFrame API 提供的是一套高层的关系操作,比函数式的 RDD API 要更加友好,门槛更低。
5)Dataframe 的劣势在于在编译期缺少类型安全检查,导致运行时出错。
2. 细说 DataSet
1)DataSet 是在 Spark1.6 中添加的新的接口。
2)与 RDD 相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表。
3)与 DataFrame 相比,保存了类型信息,是强类型的,提供了编译时类型检查。
4)调用 Dataset 的方法先会生成逻辑计划,然后 Spark 的优化器进行优化,最终生成物理计划,然后提交到集群中运行。
5)DataSet 包含了 DataFrame 的功能,在 Spark2.0 中两者得到了统一:DataFrame 表示为 DataSet[Row],即 DataSet 的子集。
区别概述
1)RDD:以 Person 为类型参数,但不了解其内部结构。
2)DataFrame:提供了详细的结构信息 schema 列的名称和类型。这样看起来就像一张表了。
3)DataSet:不光有 schema 信息,还有类型信息。
4、Spark Stage的划分
在 Spark 中,Stage 的划分是基于 RDD 之间的依赖关系,这些依赖关系分为窄依赖和宽依赖两种类型。
窄依赖指的是父 RDD 的每个分区最多被一个子 RDD 的分区所用,表现为一对一或一对多的关系,这种情况下不会有 shuffle 的产生。而宽依赖则指父 RDD 的一个分区的数据去到子 RDD 的不同分区里面,这种情况下会有 shuffle 的产生。Stage 的划分原则是从后往前,遇到宽依赖就断开,形成新的 Stage。每个 Stage 的 Task 数量由最后一个 RDD 的 Partition 数决定。ShuffleMapTask 用于提供 shuffle 数据,而 ResultTask 则用于生成最终结果。
具体来说,窄依赖允许父 RDD 的分区对应一个或多个子 RDD 分区,而宽依赖则需要等待所有父分区处理完毕。Stage 的划分是根据 RDD 之间的依赖关系形成的DAG(有向无环图),DAG 提交给DAGScheduler,后者将 DAG 划分为相互依赖的多个 Stage。每个 Stage 包含一个或多个 task,这些 task 有相同的 shuffle dependencies。Stage 的切割规则是从后往前,遇到宽依赖就切割 Stage,形成一组并行的 task 运行。这种划分方式使得 Spark 能够有效地处理大数据集,并通过并行计算加速处理速度
5、Spark Rdd机制
1). 基础意义:
RDD 在 spark 中也叫做弹性分布式数据集,是 spark 最基本的数据处理模型。RDD 在 spark 中(源码)是一个抽象类,代表一个弹性,不可变,可分区,可并行计算的集合。
2).RDD 特点:
RDD 表示只读分布区数据集,对 RDD 的改动只能通过转换操作,由一个 RDD 转换得到另一个新的 RDD,新的 RDD 包含了从其他 RDD 衍生所必要的信息。RDD 之间存在依赖,之间按照血缘关系延时计算,如果关系较长可以持久化 RDD 来切断血缘关系。
1. 分区,RDD 逻辑上是分区的,数据抽象存在,计算时通过 compute 获得每个分区的数据。如果数据时从文件系统而来,则 compute 通过读取指定文件系统获取数据,如果依赖其他 RDD,则 compute 通过转换获得数据 。
2. 只读
3. 依赖(宽窄依赖)
4. 缓存 e.checkpoint
6、Spark Shuffle理解
逻辑层面:主要从 RDD 血缘出发,从 DAG 角度讲解 shuffle,再说明 spark 容错机制
物理层面:从执行角度剖析 Shuffle 是如何发生
以下是从逻辑层面和物理层面进行讲述:
逻辑层面:RDD 血缘和容错机制
血缘:RDD 在 spark 执行后会被解析为 DAG(被称之为无向循环图),在 DAG 中最初的 RDD 为基础 RDD,之后的 RDD 产生依赖基础 RDD,子 RDD 与基础 RDD 存在依赖关系,程序运行过程中无论那个 RDD 出现问题,都会依赖这种关系在某个点重新计算生成。血缘的表现方式为宽依赖和窄依赖。
容错:
spark 程序执行过程中,可能遇到的几种失败有
Driver 出错:标记整个任务失败,需重启 Driver
Executor 出错:通常是所在的 worker 失败,会重新调度到其他 excutor 执行,重新执行的 task 会根具 RDD 血缘重新执行
Task 出错:spark 会对失败的 task 进行重试,3 次后如果任然是失败,整个任务也就失败。
数据恢复和重试都是依赖 RDD 血缘机制
宽窄依赖:
窄依赖的标准定义是:子 RDD 中的分区与父 RDD 中的分区只存在一对一的映射关系
宽依赖的标准定义是:子 RDD 中分区与父 RDD 中分区存在一对多的映射关系
宽依赖还有个名字,叫 shuffle 依赖,也就是说宽依赖必然会发生在 shuffle 操作,shuffle 也是划分 stage 的重要依据。而窄依赖由于不需要发生 shuffle,所有计算都是在分区所在节点完成,类似于 MR 中的 ChainMapper。所以说,在如果在程序中选取的算子形成了宽依赖,那么就必然会触发 shuffle
所以当 RDD 在 shuffle 过程中某个分区出现了故障,只需要找到当前对应的 Stage,而这个 Stage 必然是某个 shuffle 算子所进行划分的,找到了这个算子,就离定位错误原因越来越近了。
物理层面:Spark 物理层面对文件的 shuffle 方式有 hash shuffle 、 sort_base shuffle
Hash Shuffle:
Hash Shuffle 分为两个阶段,分别是 shuffle write 和 shuffle fetch,前者是 map 任务划分分区,输出中间结果,后者是 reduce 获取中间结果。
Hash Shuffle 整个过程中,所产生的文件数据和 reduce 数相同,每个 repartition 都有一个缓冲区用于接收结果,写满后就会输出到一个文件,用于 reduce 拉去数据结果。
Hash Shuffle 实现缺陷也很明显:产生太多文件数,缓冲区占用太多空间。对于文件数太多问题,spark 引入 File consolidation 机制,指共同输出文件以减低文件数(相同分区写同一个文件),会产生 C(cpu)*R 个文件。
Sort-Base Shuffle:
每个 map 任务最后都会只输出两个文件,一个是 data 文件,一个是 index 文件,过程采用类似 mapreduce 一样的归并排序,index 会记录每个 partition 的偏移量,write 完成后,reduce 会更具 index 得到属于自己的分区,这种情况下,shuffle 产生的结果文件问 2*M。
在基于排序的 shuffle 中,spark 还提供了一种折中方案,bypass sort-base shuffle,即当 spark 的 reduce 的任务小于 spark.shuffle.sort.bypassMergeThreshold(默认 200),任务会按照 hash shuffle 处理数据,不进行归并排序。只在 shuffle wite 后将文件合并为一个,并生成 index 文件。(其中中间会产生大量文件,只是最后被合并为一个)。
7、Spark Map和MapValue
Map会改变源 RDD,且将函数作用于 Key 和 Value,并返回一个新的 RDD
MapValue则是将函数作用于源 RDD 的 Value 且不产生新的 RDD,既:源 RDD 的分区不受到影响
8、Spark中的Order by、Sort by、Distribute by、Cluster by
Order by :order by 会对输入做全局排序,因此只有一个 Reducer(多个 Reducer 无法保证全局有序),然而只有一个 Reducer,会导致当输入规模较大时,消耗较长的计算时间
Sort by :不是全局排序,其在数据进入 reducer 前完成排序,因此,如果用 sort by 进行排序,并且设置mapred.reduce.tasks>1,则 sort by 只会保证每个 reducer 的输出有序,并不保证全局有序
Distribute by :控制在 map 端如何拆分数据给 reduce 端的。hive 会根据 Distribute by 后面的列和对应 Reduce 的个数进行数据分发,默认是采用 Hash 算法。Sort by 为每个 Reduce 产生一个排序文件。在有些情况下,你需要控制某个特定行应该到哪个 Reducer,这通常是为了进行后续的聚集操作。Distribute by 刚好可以做这件事。因此,Distribute by 经常和 sort by 配合使用。
1.Map 输出的文件大小不均;
2.Reduce 输出文件大小不均;
3. 小文件过多;
4. 文件超大;
Cluster by :除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是倒叙排序,不能指定排序规则为 ASC 或者 DESC。
9、Spark作业提交流程
spark-submit提交代码,执行new SparkContext(),在 SparkContext 里构造DAGScheduler和TaskScheduler。TaskScheduler 会通过后台的一个进程,连接 Master,向 Master 注册 Application。
Master 接收到 Application 请求后,会使用相应的资源调度算法,在 Worker 上为这个 Application 启动多个 Executer。
Executor 启动后,会自己反向注册到 TaskScheduler 中。
所有 Executor 都注册到 Driver 上之后,SparkContext 结束初始化,接下来往下执行我们自己的代码。
每执行到一个 Action,就会创建一个 Job。
Job 会提交给 DAGScheduler。
DAGScheduler 会将 Job 划分为多个 stage,然后每个 stage 创建一个 TaskSet。
TaskScheduler 会把每一个 TaskSet 里的 Task,提交到 Executor 上执行。
Executor 上有线程池,每接收到一个 Task,就用 TaskRunner 封装,然后从线程池里取出一个线程执行这个 task。
(TaskRunner 将我们编写的代码,拷贝,反序列化,执行 Task,每个 Task 执行 RDD 里的一个 partition)
10、Coalesce和Repartition
1)关系: 两者都是用来改变 RDD 的 partition 数量的,repartition 底层调用的就是 coalesce 方法: coalesce(numPartitions, shuffle = true)
2)区别: repartition 一定会发生 shuffle,coalesce 根据传入的参数来判断是否发生 shuffle 一般情况下增大 rdd 的 partition 数量使用 repartition,减少 partition 数量时使用 coalesce
11、Spark 持久化机制和checkpoint 机制区别
目的不同:cache 是为了加速计算,也就是加速后续的 job。checkpoint 则是为了在 job 运行失败的时候能够快速恢复!
存储位置不同:cache 主要使用内存,偶尔使用磁盘存储。checkpoint 为了可靠读写主要采用 HDFS 作为存储空间
对 Lineage 影响不同:cache 对 lineage 无影响。缓存的 RDD 丢失后可以通过 lineage 重新计算。如果对 RDD 进行 checkpoint,HDFS 因为是可靠存储的,所以不需要再保存 lineage 了
应用场景不同:cache 机制适用于会被多次读取,占用空间不是特别大的 RDD。checkpoint 机制则是适用于数据依赖关系特别复杂,重新计算代价高的 RDD,比如某 RDD 关联的数据过多、计算链过长、被多次重复使用。
12、Spark由哪几个部分构成?
Master 节点:常驻 Master 进程,该进程负责管理所有的 Worker 节点。(分配任务、收集运行信息、监控 worker 的存活状
Worker 节点:常驻 Worker 进程,该进程与 Master 节点通信,还管理 Spark 任务的执行。(启动 Executor,监控任务运行状态)
Executor 执行器:Executor 是一个 JVM 进程,是 Spark 计算资源的单位。可以运行多个计算任务。
Task: Spark 应用会被拆分为多个计算任务,分配给 Executor 执行。Task 以线程的方式运行在 Executor 中。
13、Map 是类似于桶数组的形式,类比说一下RDD 的内部结构
RDD 就像一个分布式数组,每个子 part 含有相同类型的元素,但是元素可以分布在不同的机器上。
14、Spark 中 DAG 是如何形成的
DAG 详解
DAG(Directed Acyclic Graph)叫做有向无环图,原始的 RDD 通过一系列的转换就形成了 DAG,根据 RDD 之间依赖关系的不同将 DAG 划分成不同的 Stage(调度阶段)。
对于窄依赖,partition 的转换处理在一个 Stage 中完成计算。
对于宽依赖,由于有 Shuffle 的存在,只能在 parent RDD 处理完成后,才能开始接下来的计算,因此宽依赖是划分 Stage 的依据。
DAG 的边界:
开始:通过 SparkContext 创建的 RDD
触发 Action:一旦触发 Action 就形成了一个完整的 DAG
DAG 划分 Stage:
1)一个 Application 有一个或者多个 job, 一个 job 对应一个 DAG
2)一个 job 分为不同的 stage
3)一个 stage 下面有一个或者多个 TaskSet
4)一个 TaskSet 有很多 Task(一个 Task 就是所需的 cpucores)
5)一个 TaskSet 就对应一个 RDD, 很多 RDD 称为 TaskSets
理解:
1. 一个 Spark 的 Application 应用中一个或者多个 DAG(也就是一个 Job), 取决于触发了多少次 Action
2. 一个 DAG 中会有不同的阶段 /stage,划分阶段 /stage 的依据就是宽依赖
3. 一个阶段 /stage 中可以有多个 Task,一个分区对应一个 Task
4.spark 会根据shuffle/ 宽依赖使用回溯算法来对 DAG 进行 Stage 划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的 stage/ 阶段中。
15、Spark内存管理机制
在进行分析 Spark 内存管理前,我们先看下 Spark 架构图:
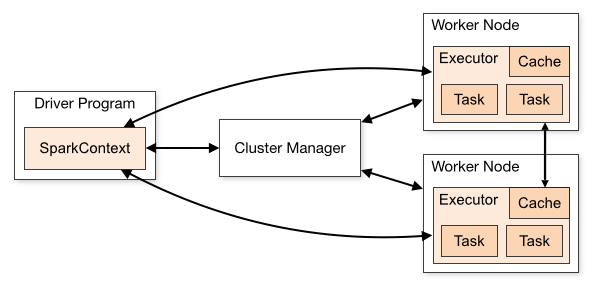
从上图可以看出,Spark Application 中包括两个 JVM 进程:Driver 和 Executor
Driver是主控进程,负责创建 SparkSession/SparkContext,提交 Job,将 Job 转化为 Task,协调执行器之间的 Task 执行。
Executor主要负责执行具体的计算任务,并将结果返回给 Driver。
Spark 的内存管理在这两个部分中也是有所不同的,其中 Driver 内存管理比较简单,这里不做讲解,我们主要分析的是 Executor 的内存管理。
Executor 内存分为两种(如下图所示):In-Heap memory 和 External memory
On-Heap 内存(In-Heap memory):对象在 JVM Heap 上分配并由 GC 绑定;
Off-Heap 内存(External memory):对象通过序列化的方式分配在 JVM 之外的内存中,由应用程序管理,不受 GC 约束;
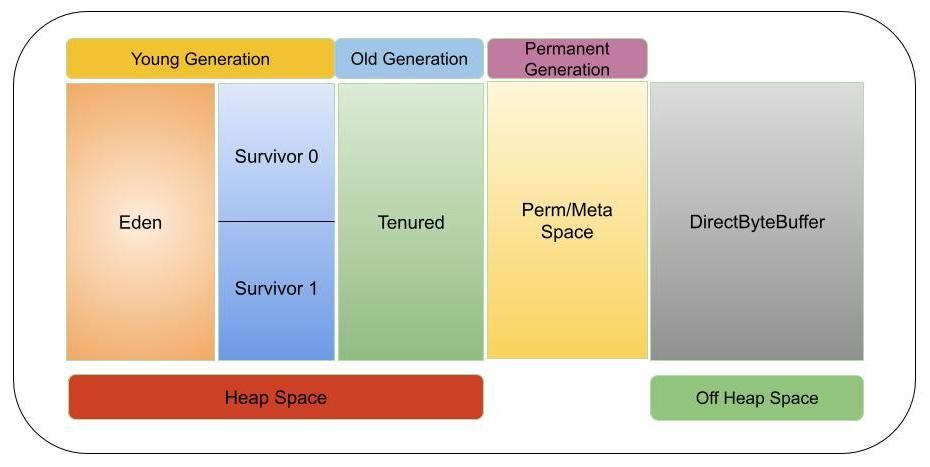
On-Heap 内存
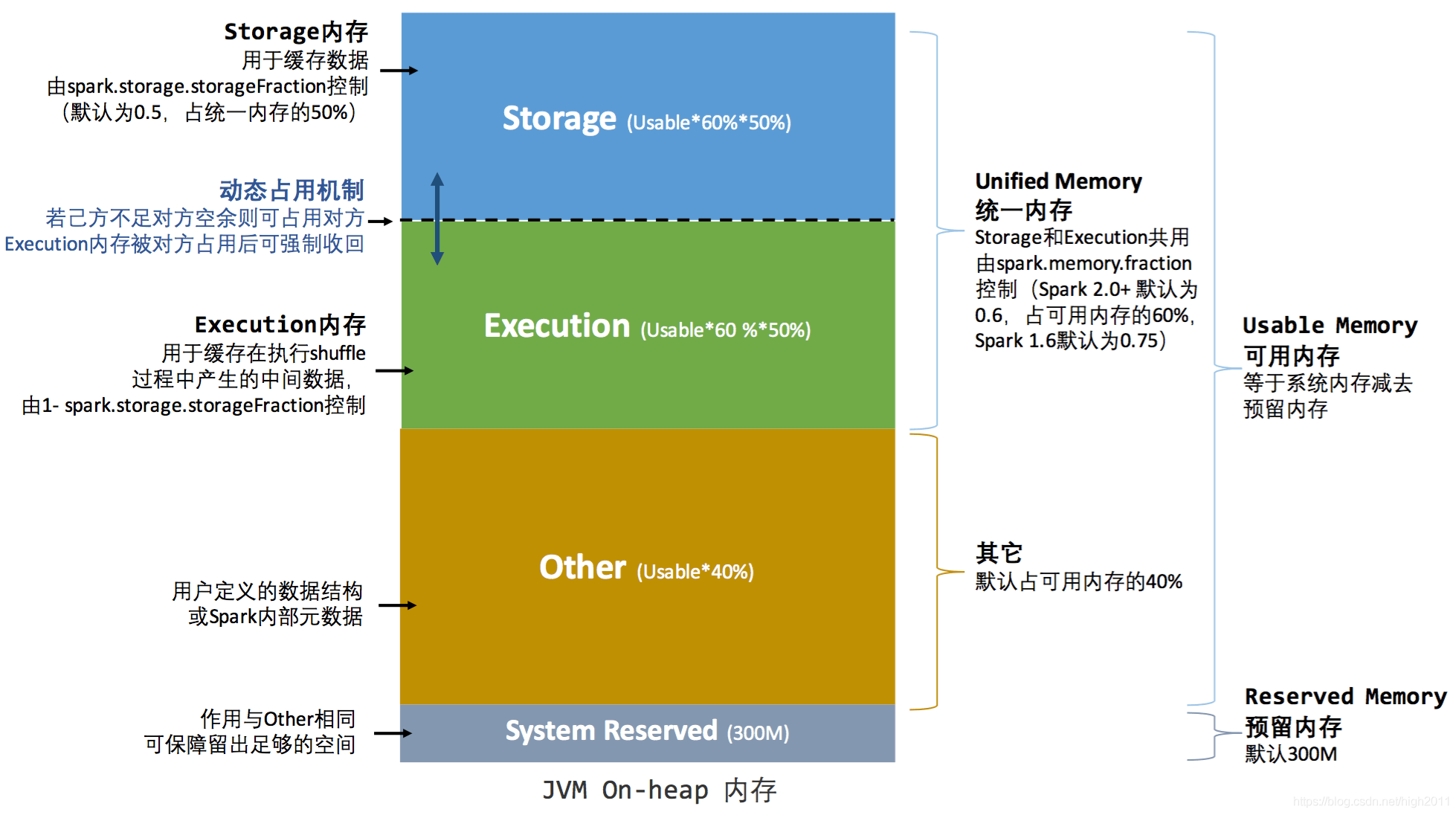
On-Heap 内存即为堆内内存,它的大小由提交作业时指定 --excutor-memory 参数配置。Spark 对内存的管理是一种逻辑上的规划管理,具体内存的申请和释放由 JVM 完成,Spark 只是在 JVM 内存申请后和释放前记录这些内存(这是因为 Spark 的内存管理是基于 JVM 内存管理的),对于序列化对象可以精确计算实际占用内存,对于非序列化对象,占用内存采用周期采样估算得出,这样就导致实际可用内存小于 spark 记录的可用内存,容易导致 OOM 异常,但通过划分不同区域进行管理,可一定程度上减少了异常的出现。下图为 Spark 堆内内存的分配图(图例为统一内存管理):
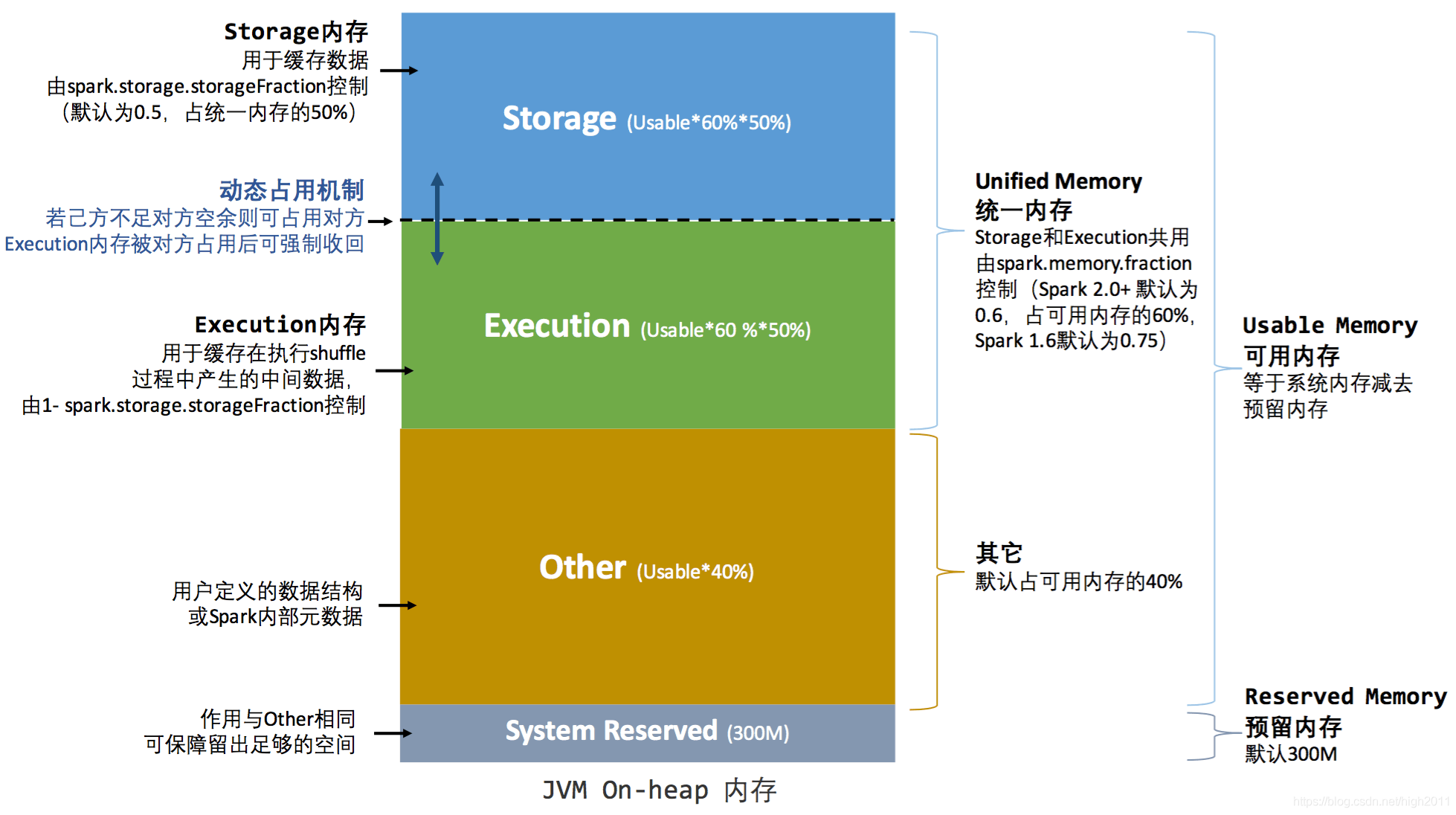
从上图我们可以看出,Spark 堆内内存分为四个部分:
Storage:用于缓存分布式数据集,比如 RDD Cache、广播变量等等
Execution:用来执行分布式任务。分布式任务的计算,主要包括数据的转换、过滤、映射、排序、聚合、归并等环节
Other:提供 Spark 内部对象、用户自定义对象的内存空间
System Reserved:不受开发者控制,它是 Spark 预留的、用来存储各种 Spark 内部对象的内存区域;
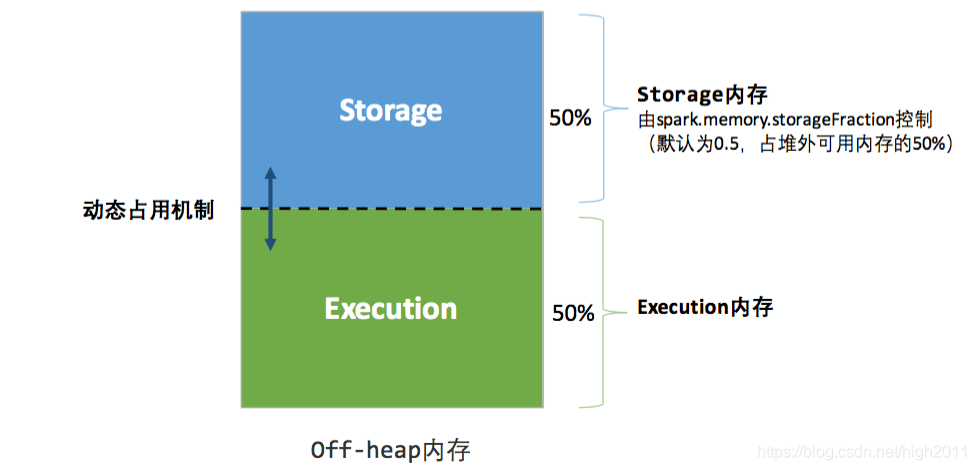
Off-Heap 内存
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。利用 JDK Unsafe API(从 Spark 2.0 开始,在管理堆外的存储内存时不再基于 Tachyon,而是与堆外的执行内存一样,基于 JDK Unsafe API 实现),Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
下图为 Spark 堆外内存的分配图(图例为统一内存管理):
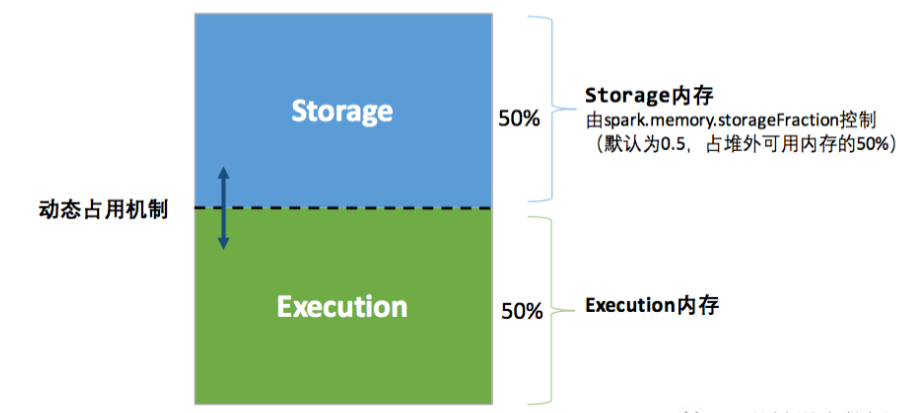
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小。除了没有 other 空间,堆外内存与堆内内存的划分方式基本相同,所有运行中的并发任务共享存储内存和执行内存。
内存管理机制
了解了 Spark 的内存分类后,我们就来看下 Spark 内存的管理机制。Spark 的内存管理机制分为两种(如下图所示):静态内存管理和统一内存管理
静态内存管理(Static Memory Management):将内存静态地分成两个固定的分区,用户在启动前可对其进行配置
统一内存管理(Unified Memory Manager):将内存进行统一管理,支持 Storage 和 Execution 内存动态占用
下面对这两种内存管理机制进行详细的介绍:
静态内存管理
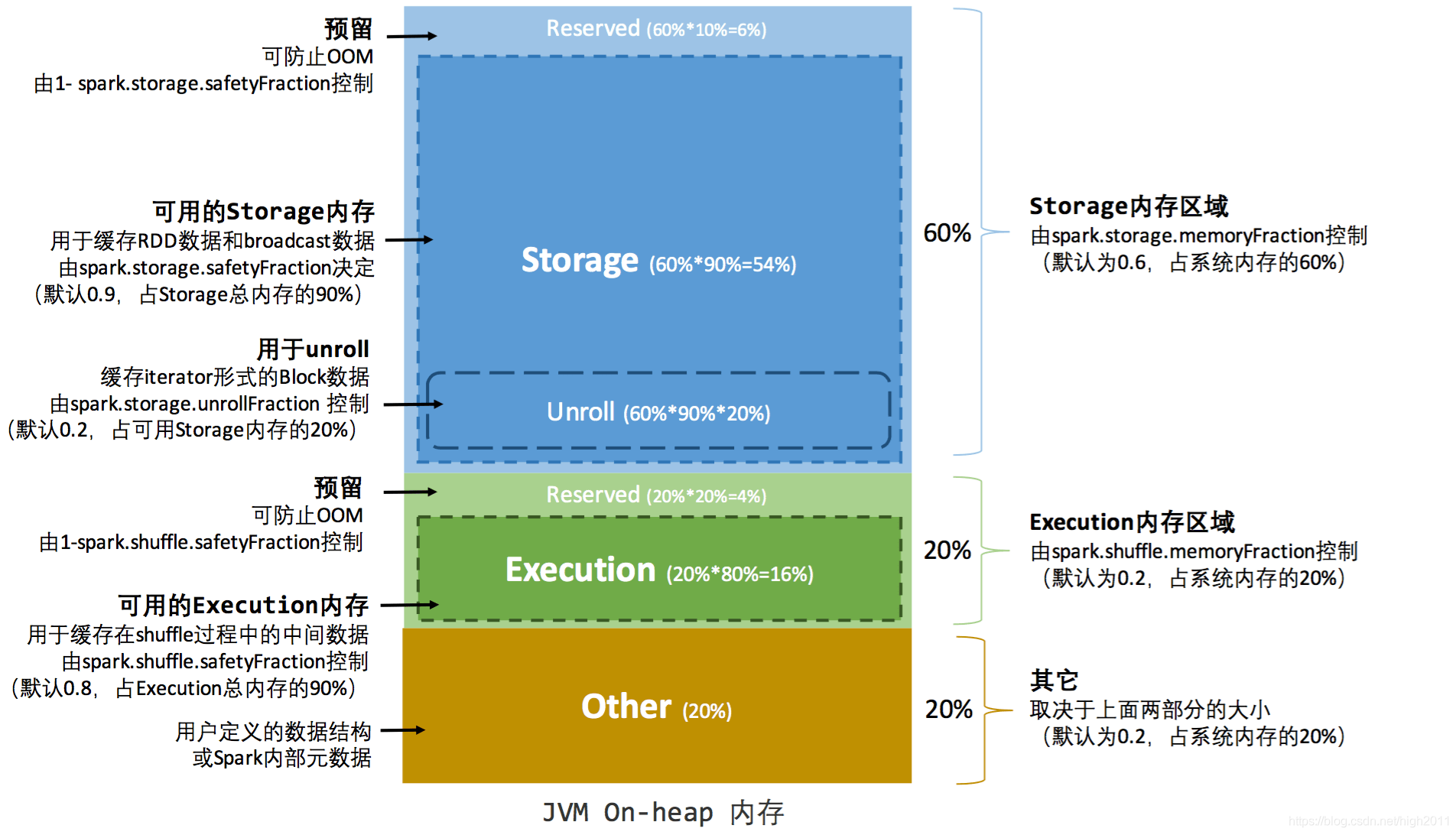
Spark 的静态内存管理将内存静态地分成两个固定的分区,Storage Memory 和 Execution Memory 等内存的大小在应用程序处理过程中是固定的,但用户可以在应用程序启动前对其进行配置。设置参数如下可参考:

静态内存管理图示 - 堆内
静态内存管理图示 - 堆外
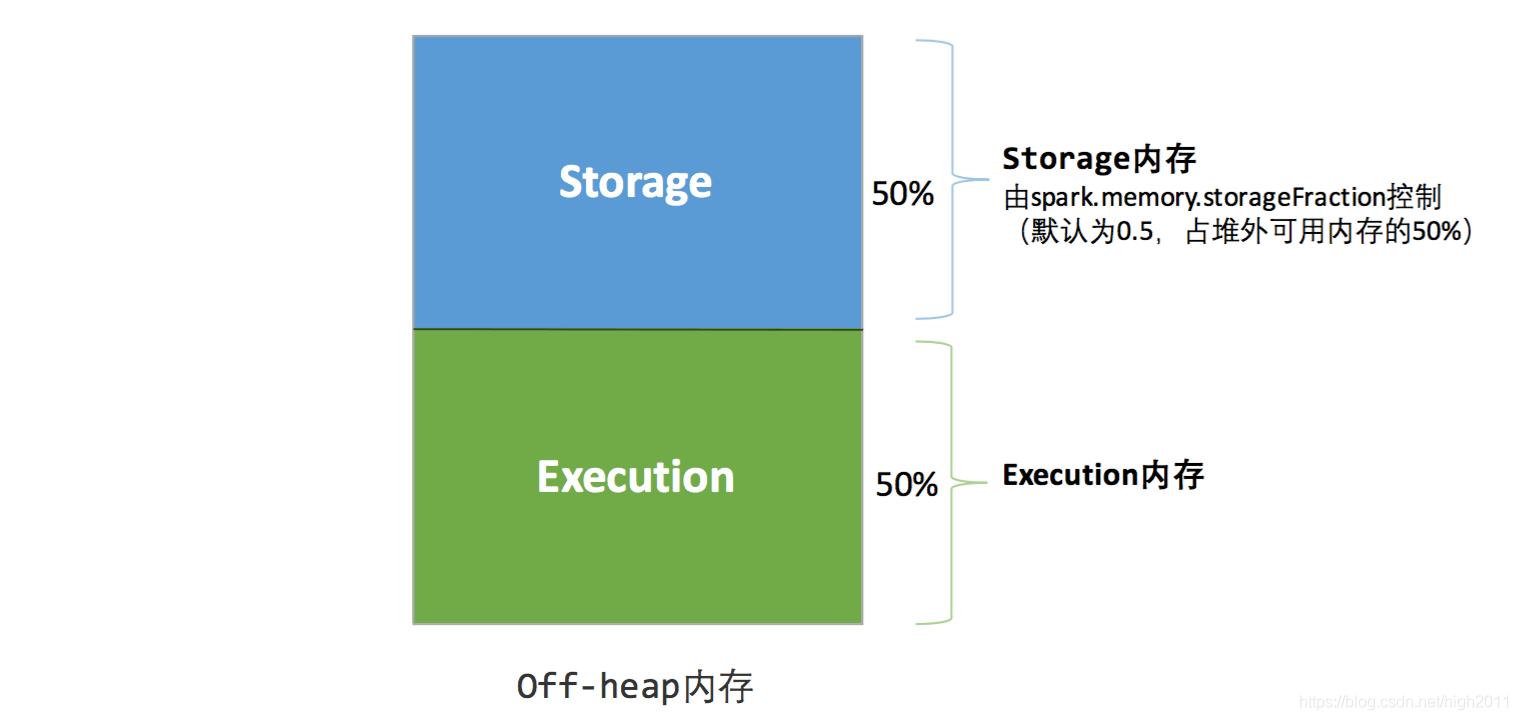
作为传统的内存管理模型,它的优缺点还是很明显的:
优点:实现比较简单
缺点:
1. 尽管存储内存有可用空间,但无法使用,并且由于执行程序内存已满而会导致磁盘溢出(反之亦然)。
2. 静态内存管理不支持使用堆外内存进行存储,所以全部分配给执行空间。
注:从 Spark 1.6.0 开始,采用新的内存管理器替代静态内存管理器,静态管理方式任然被保留,可通过 spark.memory.useLegacyMode 参数启用。但静态内存分配方法在 Spark 3.0 中被淘汰了,不能使用了
动态内存管理
Spark 从 1.6.0 版本开始,采用新的内存管理器代替了静态内存管理器,为 Spark 提供动态内存分配。它分配一个内存区域作为存储和执行共享的统一内存容器。当不使用执行内存时,存储内存可以获得所有可用内存,反之亦然。如果任何存储或执行内存需要更多空间,一个名为 acquireMemory() 的函数将扩展其中一个内存池并缩小另一个内存池。借用的存储内存可以在任何给定时间被逐出。然而,由于实现的复杂性,借用的执行内存不会在第一个设计中被逐出。
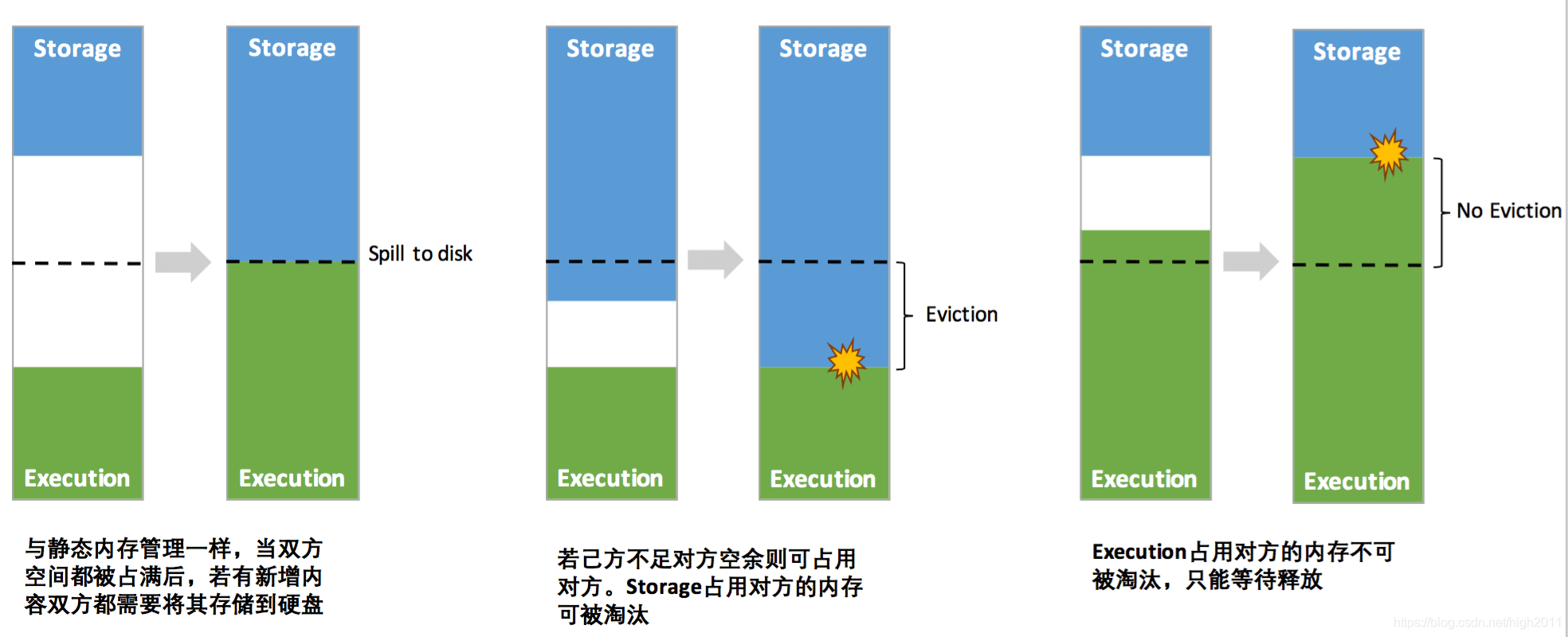
动态内存管理机制的动态占用规则如下:
只有在 Execution memory 中没有使用 blocks 时,Storage memory 才能从 Execution memory 中借用空间。
如果 Storage memory 中没有使用 blocks,执行内存也可以从 Storage memory 中借用空间。
如果 Execution memory 中的 blocks 被 Storage memory 占用,而 Execution 需要更多的内存,可以强制驱逐 Storage Memory 占用的多余 blocks
如果 Storage Memory 中的 blocks 被 Execution memory 使用,Storage 需要更多的内存,则不能强行驱逐 Execution Memory 占用的多余 blocks;它最终将拥有更少的内存区域。它会等到 Spark 释放掉 Execution memory 存储的多余 block,然后占用它们。
动态内存占用图示如下:
动态内存管理图示 - 堆内
动态内存管理图示 - 堆外
动态内存管理机制是用来解决静态内存管理机制不够灵活的问题的,它的优点如下:
1. 存储内存和执行内存之间的边界不是静态的,在内存压力的情况下,边界会移动,即一个区域会通过从另一个区域借用空间来增长。
2. 当应用程序没有缓存和传播时,执行会使用所有内存以避免不必要的磁盘溢出。
3. 当应用程序有缓存时,它会保留最小的存储内存,这样数据块就不会受到影响。
4. 这种方法为各种工作负载提供了合理的开箱即用性能,而无需用户了解内存如何在内部划分方面的专业知识。
深入底层源码
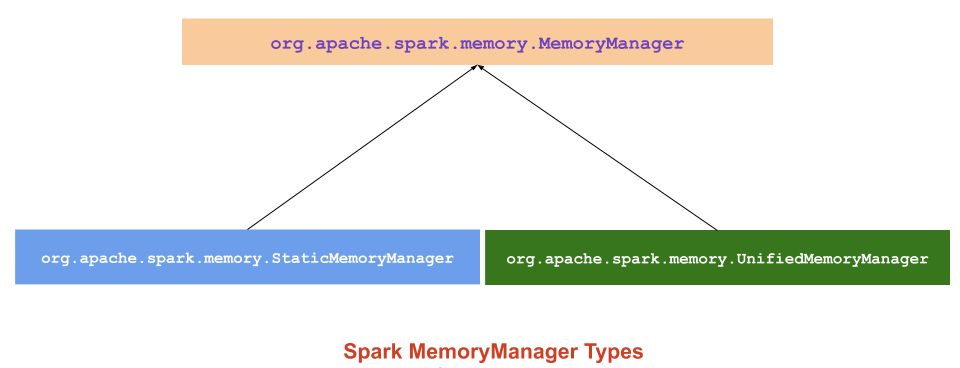
Spark 内存管理相关类都在 spark core 模块的 org.apache.spark.memory 包下。
在 Spark3.0 之前,Spark 有两种内存管理模式,静态内存管理 (Static MemoryManager) 和动态(统一)内存管理(Unified MemoryManager)
这个包实现了 Spark 的内存管理系统。该系统由两个主要组件的组成,即 JVM 范围内的内存管理和单个任务的内存管理:
MemoryManager:管理 Spark 在 JVM 中的总体内存使用情况。此组件实现了在任务之间划分可用内存以及在存储(缓存和数据传输使用的内存)和执行(计算使用的内存,如混洗、联接、排序和聚合)之间分配内存的策略。
TaskMemoryManager:管理各个任务分配的内存。任务与 TaskMemoryManager 交互,从不直接与 JVM 范围的 MemoryManager 进行交互。
在内部,这些组件中的每一个都有额外的内存记账抽象:
MemoryConsumer:是 TaskMemoryManager 的客户端,对应于任务中的单个运算符和数据结构。TaskMemoryManager 从 MemoryConsumers 接收内存分配请求,并向使用者发出回调,以便在内存不足时触发溢出。
MemoryPool:是 MemoryManager 用来跟踪存储和执行之间的内存分配的记账抽象。
示意图:

MemoryManager 有两种实现,它们处理内存池大小的方式各不相同:
UnifiedMemoryManager:Spark 1.6+ 中的默认设置强制执行存储和执行内存之间的软边界,允许通过从另一个区域借用内存来满足一个区域中的内存请求。
StaticMemoryManager:通过静态划分 Spark 的内存并防止存储和执行相互借用内存,在存储和执行内存之间实施硬边界。仅出于传统兼容性目的保留此模式。
在 Spark3.0 之后,静态内存管理被淘汰了,因此只剩下动态(统一)内存管理(Unified MemoryManager),因此内存管理源码有了较大改动。
MemoryConsumer:是 TaskMemoryManager 的客户端,对应于任务中的单个运算符和数据结构。TaskMemoryManager 从 MemoryConsumers 接收内存分配请求,并向使用者发出回调,以便在内存不足时触发溢出。
MemoryMode:Spark 的内存类型有两种:堆内和堆外
SparkOutOfMemoryError:当任务无法从内存管理器获取内存时,会引发此异常。我们应该使用 throw this 异常,而不是抛出 OutOfMemoryError,这会杀死执行器,这只会杀死当前任务。
TaskMemoryManager:管理单个任务分配的内存
TooLargePageException:页面过大异常
16、Spark数据倾斜处理
数据倾斜的表现:
1.Executor lost,OOM,Shuffle 过程出错;
2.Driver OOM;
3. 单个 Executor 执行时间特别久,整体任务卡在某个阶段不能结束;
4. 正常运行的任务突然失败;
数据倾斜的处理方案:
1. 使用 Hive 预处理:适用于导致数据倾斜的是 Hive 表,Hive 表中的数据本身不均匀;
2. 过滤导致倾斜的 key:适用于只有少数几个热点 key,并且过滤之后对结果没影响;
3. 提高 shuffle 操作的并行度;
4. 两阶段聚合:局部 + 全局;
5. 将 reduce join 转为 map join:适用于一个 RDD 或表的数据量比较小,即一个大表和一个小表的情况;
6. 采样倾斜 key 并分拆 join 操作。适用于两个表都很大,但其中某一个 RDD/Hive 表中的少数几个 key 的数据量过大,而另一个 RDD/Hive 表中的所有 key 都分布比较均匀。采用计算出最多的几个 key,将这几个 key 对应的数据从原来的 RDD 中拆分出来,形成一个单独的 - RDD,并给每个 key 都打上 n 以内的随机数作为前缀;
7. 使用随机前缀和扩容 RDD 进行 join:适用于 RDD 中有大量的 key 导致数据倾斜;
17、Spark 任务提交流程
1.Spark-Shell 提交任务,向 RM 申请资源;
2.RM 分配 container,在对应 NodeMANAGER 启动 AM,然后 AM 启动 driver;
3.Driver 向 ResourceManager 申请资源 Executor;
4.RM 返回 container 给 driver;
5.Driver 在相应 NodeMANAGER 启动 executor;
6.Executor 向 driver 反向注册;
7.Executor 全部注册完,Driver 开始执行 main 函数;
8.Driver 执行函数时,遇到 action 算子就会触发一个 job,根据宽依赖划分 stage,每个 stage 生成 taskSet,将 task 分发到 Executor 上执行;
18、ReduceByKey和GroupByKey的区别
从 shuffle 角度:ReduceByKey 和 GroupByKey 都存在 shuffle 的操作,但是 ReduceByKey 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落磁盘的数据量(io);而 GroupByKey 只是进行分组,不存在数据量减少的问题,ReduceByKey 的性能高
从功能角度:ReduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚合。所以在分组聚合的场合下,推荐使用 reduceByKey,而仅仅只是分组而不需要聚合的,那么只能使用 GroupByKey。
19、算子解释
ReduceByKey、FoldByKey、AggregateByKey、CombineByKey 区别
ReduceByKey 没有初始值 分区内和分区间逻辑相同
foldByKey 有初始值 分区内和分区间逻辑相同
aggregateByKey 有初始值 分区内和分区间逻辑可以不同
combineByKey 初始值可以变化结构 分区内和分区间逻辑不同
算子集合:
combineByKey:最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。 combineByKey: 方法需要三个参数 第一个参数表示:将相同 key 的第一个数据进行结构的转换,实现操作 第二个参数表示:分区内的计算规则 第三个参数表示:分区间的计算规则。
foldByKey:当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey
aggregateByKey:aggregateByKey 是将数据根据不同的规则分别进行不同的分区内计算和分区间计算,规则分别设立
aggregateByKey 的返回值和初始化值必须相同
aggregateByKey 算子是函数柯里化,存在两个参数列表:
第一个参数列表中的参数表示初始值
第二个参数列表中含有两个参数
1. 第一个参数表示分区内的计算规则
2. 第二个参数表示分区间的计算规则
groupByKey:将数据源的数据根据 key 对 value 进行分组,形成一个对偶元组,元组的第二个元素是 value,groupBy 分组后的元组第二个元素是 KV。
reduceByKey:将数据按照相同的 Key 对 Value 进行聚合
partitionBy:将数据按照指定 Partitioner 重新进行分区。隐式转换为 PairRDDFunctions,二次编译。 区别于 coaleas,repartition 是数量上的改变,二 partitionBy 是功能上的改变。
subtract:前一个 RDD 元素为主,去除两个 RDD 中重复元素,将其他元素保留下来
union:对原 RDD 和参数 RDD 求并集后返回一个新的 RDD,要求类型相同
intersection:对源 RDD 和参数 RDD 求交集后返回一个新的 RDD,要求类型相同
repartition:该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。对于分区数多少的 RDD 都可以转换,因为无论如何都会经 shuffle 过程。
coalesce:根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率。spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本 coalesce 方法默认不会打乱分区重新组合,容易导致数据倾斜 但 coalease 还有第二个参数,默认为 false,不 shuffle,设置为 true 即可进行 shuffle 让数据变的均衡。
glom:将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
flatMap:将处理的数据进行扁平化后再进行映射处理
mapPartitionsWithIndex:将待处理的数据以分区为单位发送到计算节点进行处理
mapPartitions: map 和 mapPartition 的区别:map 算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。是串行,效率低 。mapPartitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变,所以可以增加或减少数据。并行,效率高,但消耗内存,容易造成内存溢出。
20、spark小文件处理
1. 合并小文件:
在读取时合并:使用 Spark 的
coalesce或repartition方法在读取数据时合并小文件。`coalesce` 减少分区数量,而repartition可以根据需要增加或减少分区数量。使用 Hadoop 文件格式:如果数据存储在 HDFS 上,可以考虑使用像 Parquet 或 ORC 这样的列式存储格式,这些格式天然支持合并小文件。
2. 避免产生小文件:
在写入数据时,合理设置分区数,以减少输出的小文件数量。
在数据转换过程中,注意数据倾斜和分区策略,避免某些分区数据量过小。
3. 使用高效的数据存储格式:
使用像 Parquet 或 ORC 这样的高效文件格式,它们可以更好地处理小文件问题,同时提供更好的压缩和编码特性。
4. 调整 Spark 配置:
调整 Spark 作业的配置,比如
spark.sql.files.maxPartitionBytes和spark.sql.files.openCostInBytes,以控制读取文件时的分区大小和行为。
5. 合并文件后再处理:
在数据处理之前,使用外部工具(如 Hadoop 的
FileCrush或自定义脚本)合并小文件,然后再用 Spark 进行处理。
6. 使用 Spark Structured Streaming:
如果是流处理场景,可以考虑使用 Spark Structured Streaming 的文件源选项,它可以有效地处理文件夹中不断累积的小文件。
