

1.用户中心现状
1.1 查询方式
用户中心查询操作使用 【CompletableFuture】 + 【自定义线程池】 的方式实现,所有查询均为单表操作, 将查询结果在应用层组合后返回给调用方;
1.2 强一致性
用户中心使用读写分离方案,对于强一致性的请求,读请求也需要强制读取主库,但很多操作使用【自定义线程池】,实现方案为:filter 拦截需要读取主库的 url,需要将上下文透传到【自定义线程池】,配置 Mybatis 拦截器 (aop 亦可),根据透传的上下文,使用 Sharding jdbc 设置强制操作主库:HintManagerHolder.isMasterRouteOnly()
1.3 上下文透传
父子线程透传:
父线程透传给子线程可以使用 java 提供的 InheritableThreadLocal
提交线程与线程池透传:
但对于使用线程池等会池化复用线程的执行组件的情况,线程由线程池创建好,并且线程是池化起来反复使用的;这时父子线程关系的 ThreadLocal 值传递已经没有意义,应用需要的实际上是把 【任务提交给线程池时】的 ThreadLocal 值传递到 【任务执行时】。
(a) 使用 TtlRunnable TtlCallable 修饰 Runnable Callable
(b) 使用 TtlExecutors 修饰线程池
(c) 参考文档:https://github.com/alibaba/transmittable-thread-local
1.4 线程池配置
aysncTaskExecutor(原有线程池,上下文透传、强一致性线程池,用于有查询需求的写操作,保证读取请求读取主库、强一致性 )
CorePoolSize = 80 MaxPoolSize = 500 QueueCapacity = 2000
TaskExecutorConfig implements AsyncConfigurer(原有线程池,@Async 时使用,用于给第三方异步发送消息 )
CorePoolSize = 80 MaxPoolSize = 500 QueueCapacity = 2000
cacheThreadPoolExecutor(C 端老师增加读取缓存线程池 )
CorePoolSize = 80 MaxPoolSize = 500 QueueCapacity = 2000
transactionThreadTaskPool(C 端老师增加缓存后、写操作异步刷新缓存需要等数据库提交后 refresh)
CorePoolSize = 80 MaxPoolSize = 500 QueueCapacity = 2000
2.根据学员号查询接口异常
/v2/students/search/code
2.1 批量查询学员
2.1.1 问题
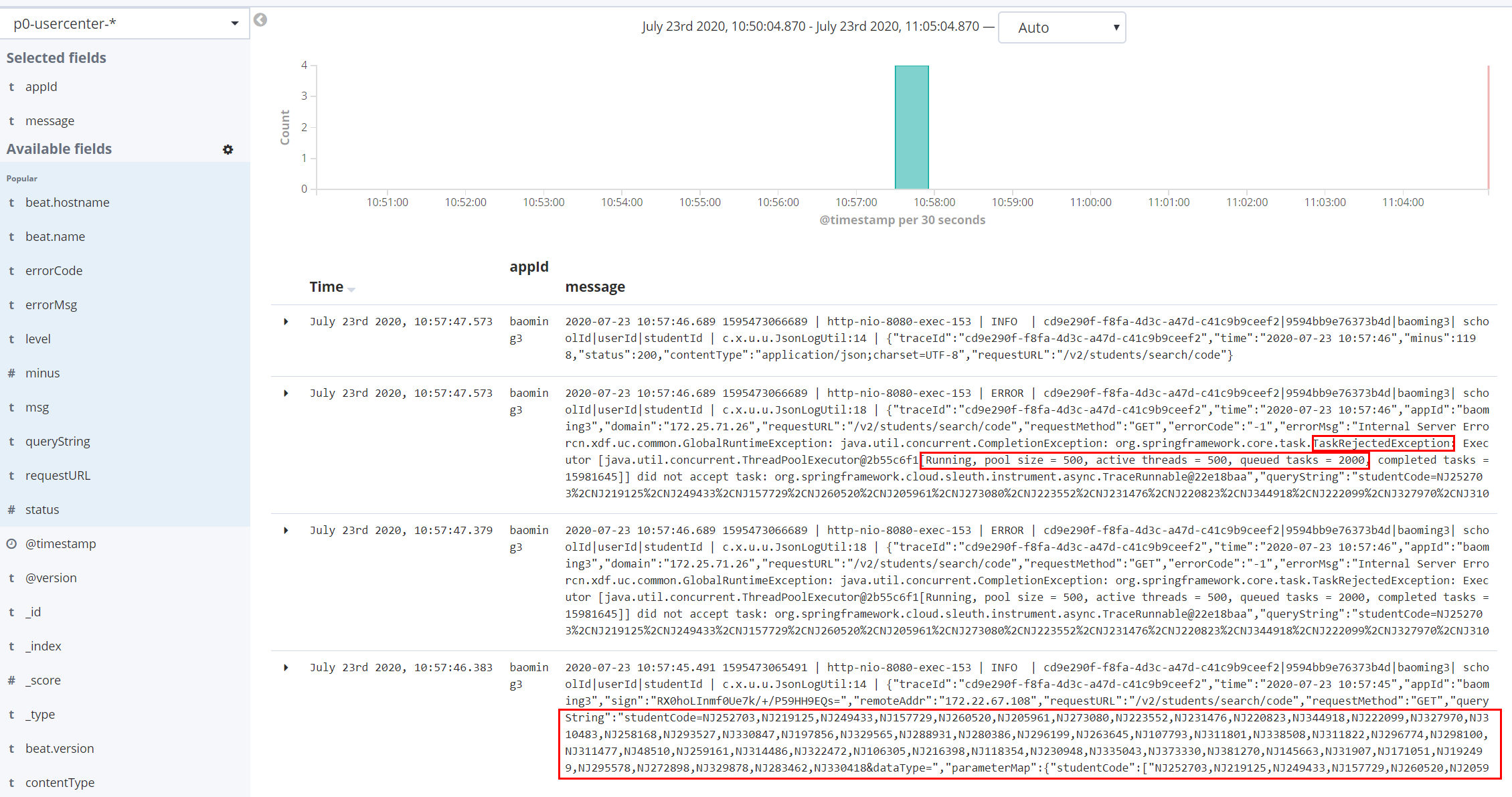
当参数学员号较多、且请求量稍大时,会出现 TaskRejectedException 异常
2.1.2 分析
C 端加缓存改造后,将批量学员号批量查询改为遍历查询缓存、缓存无查询数据库 refresh,但此时学员号较多,每个学员号都会启动一个线程查询、直到cacheThreadPoolExecutor队列和线程达到上限采用默认抛弃 (拒绝) 策略。
同一时刻 930 批量请求将线程池打满

跟踪单个请求
2.2.3 方案
伟华老师已经将根据学员号查询改为批量查询
2.2 单表查询后数据组合方式
2.2.1 问题
service 层组合学员、学员号信息,使用 CompletableFuture 默认的 ForkJoin 框架提供的线程池,未使用自定义线程池,ForkJoinPool 是典型的异步任务线程池,当大量请求从 tomcat 线程池打过来时,会将请求打到队列、异步处理,请求方可能会超时,不适合做实时 api 服务
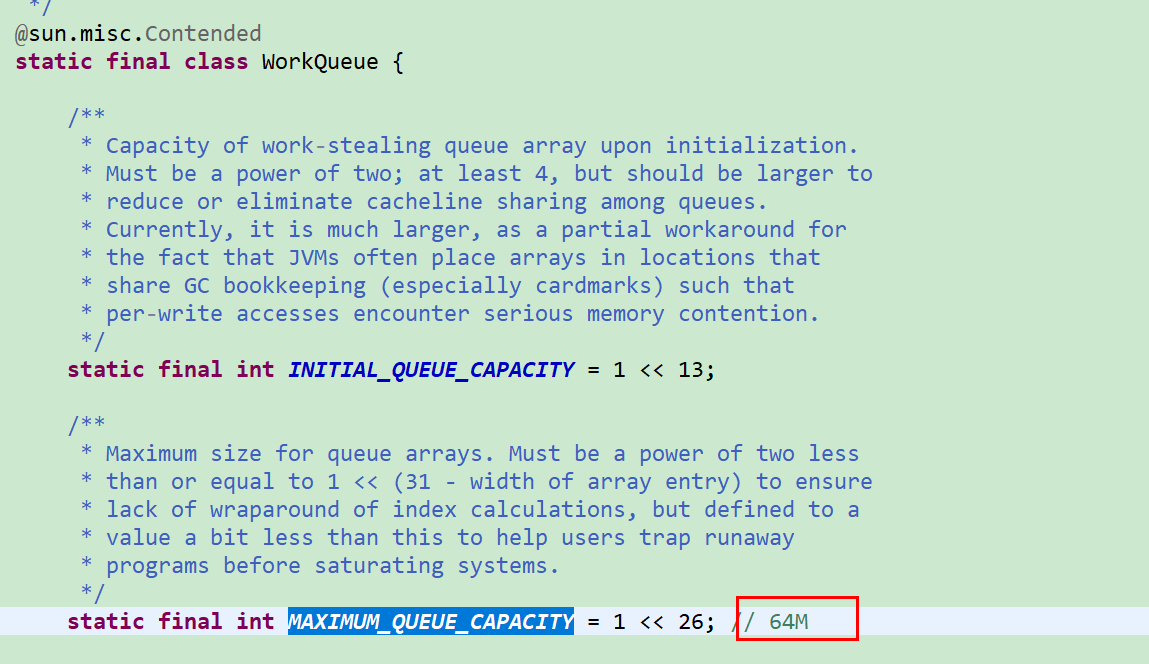
ForkJoinPool 默认线程池配置为:
队列数量:WorkQueue MAXIMUM_QUEUE_CAPACITY = 1 << 26; // 64M
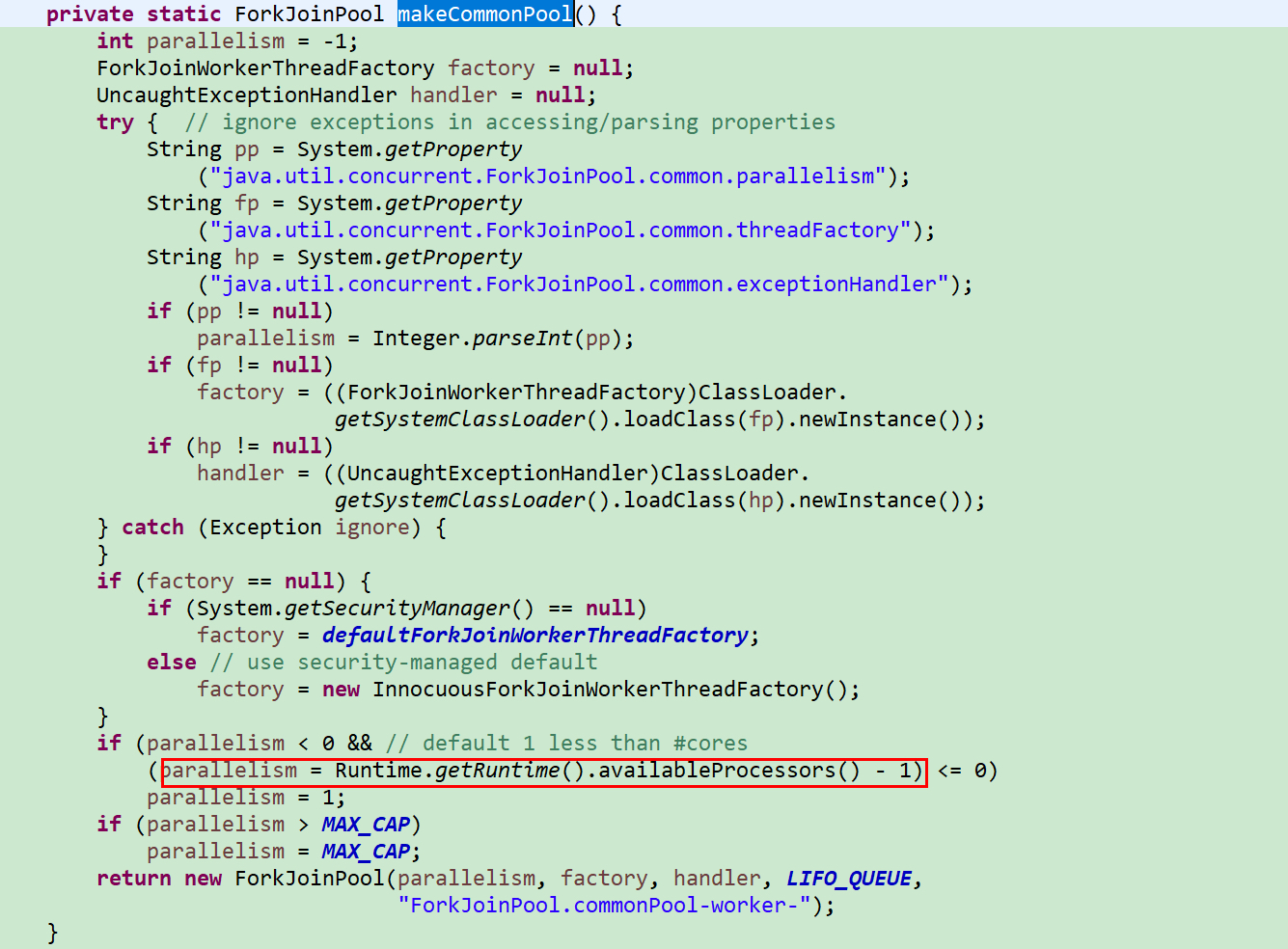
线程数量:cpu 可用 core - 1
2.2.2 方案
(a) 使用自定义线程池,改造简单、但使用 CompletableFuture 方式适合做任务计算、而非实时 api 服务。
(b) 直接使用 tomcat 主线程,串行请求单表数据组合可能会导致 RT 升高,好处是不用切换线程,有问题会直接抛出,而不是自定义线程池内部消化、且易维护。
3.全链路压测服务不可用
3.1 问题
6 万并发用户中心服务不可用:response:{"State":0,"Error":"【用户中心系统】异常,请稍后再试。此时用户中心无法接收处理后续连接请求,重启应用才能恢复,需要用户中心相关老师协助配合排查优化;用 户中心异常时压测时间点:(7 月 22 日 00:06/00:20/00:33/00:51)
3.2 用户、订单中心对比分析
吞吐率、响应时间对比:用户中心 (6 台)、订单中心 (3 台)
订单单台机器请求量、RT 分位图,每分钟请求量 6k、最大 RT0.2 秒、平均 5ms
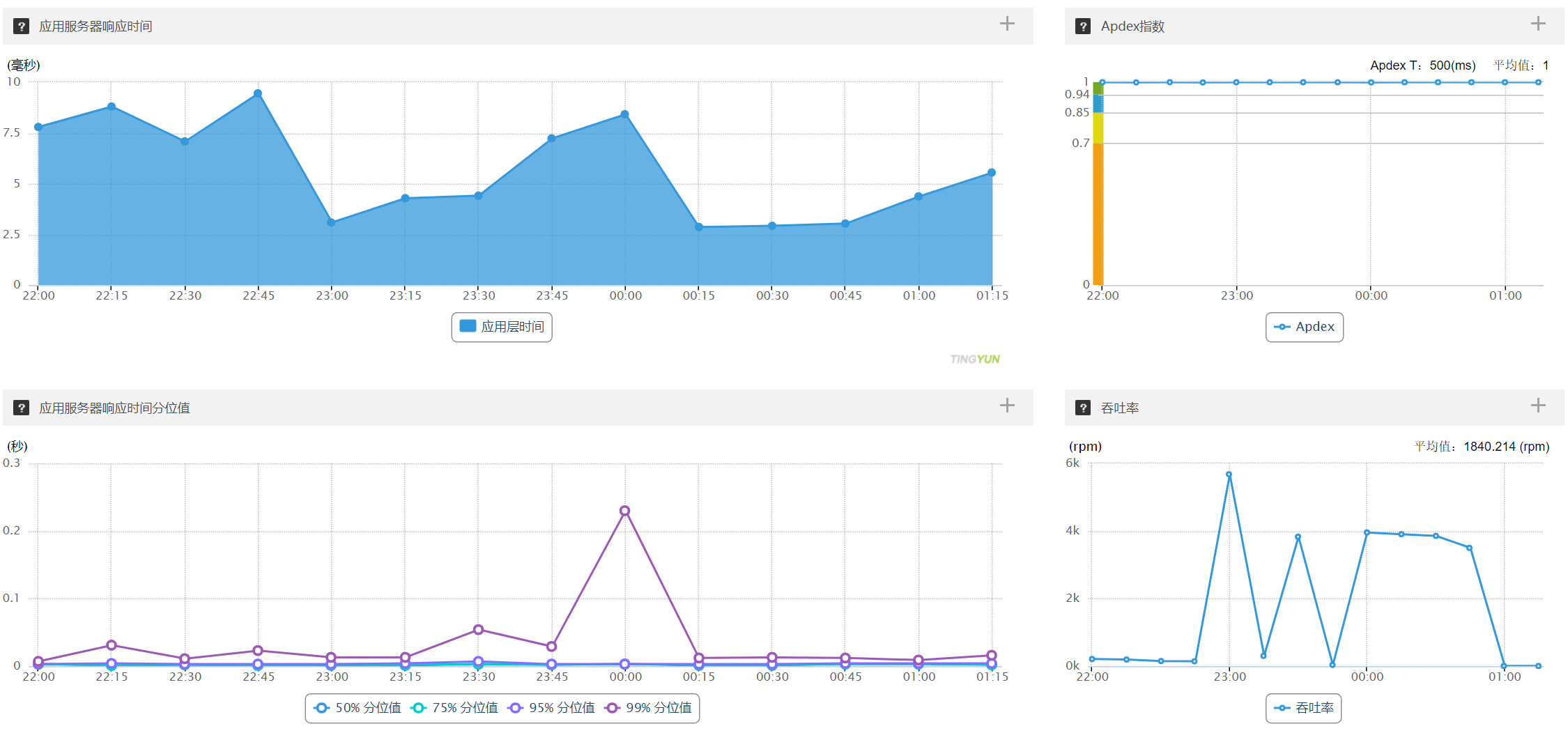
用户中心单台机器请求量、RT 分位图,每分钟请求量 7.5k、最大 RT 9 秒左右、平均 500ms
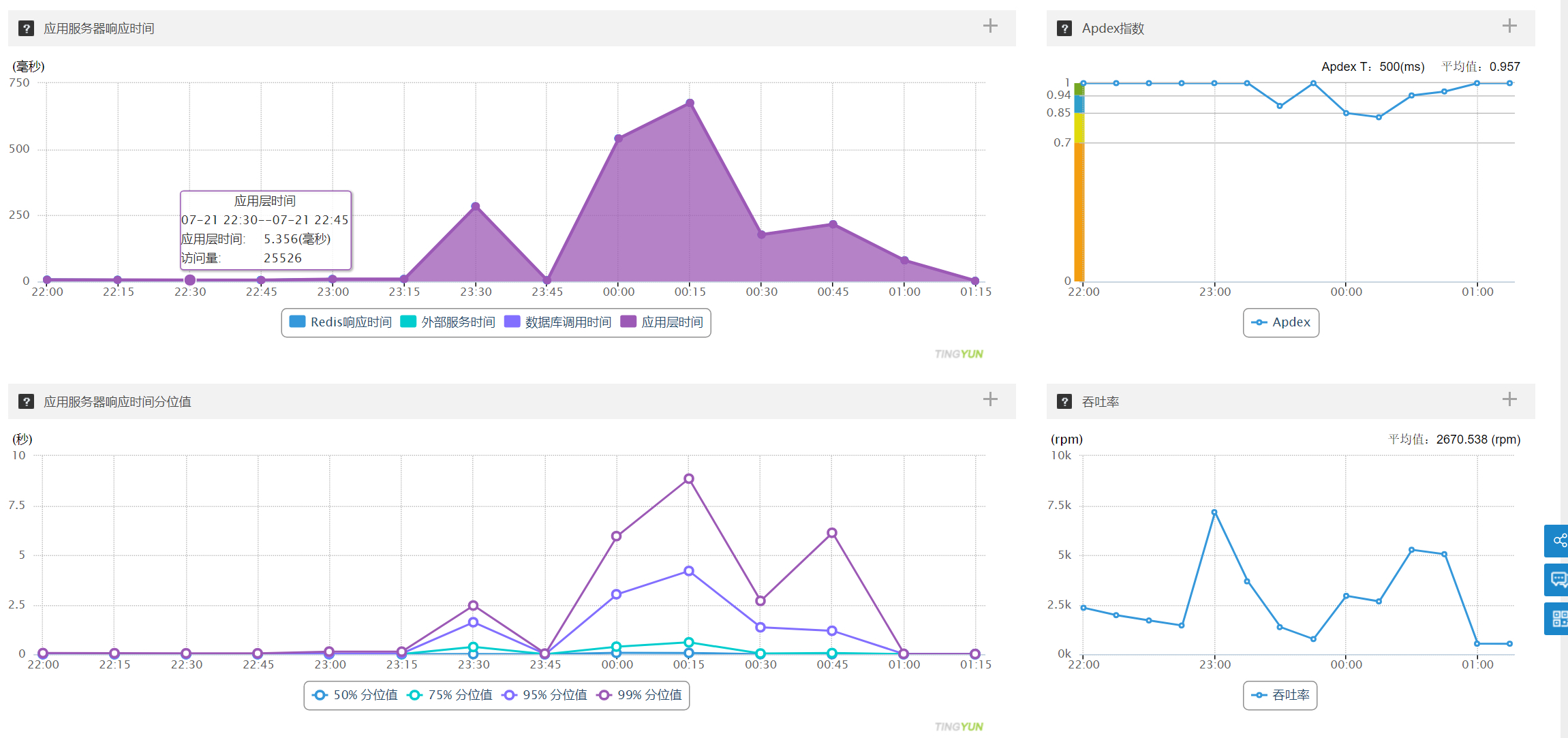
3.3 中间件、数据库分析
3.3.1 事务、DB、缓存负载分析
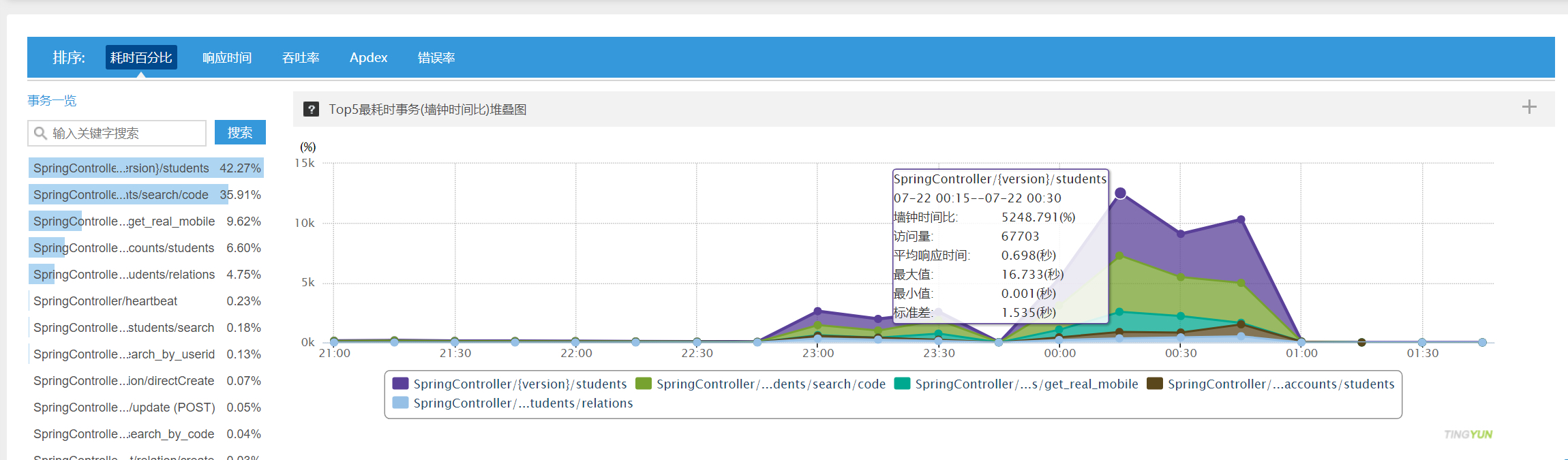
(a) 事务分析
前三名分别是:根据studentId查询学员、根据studentCode查询学员、查询真实手机号;最大响应时间长达 16.733 秒;
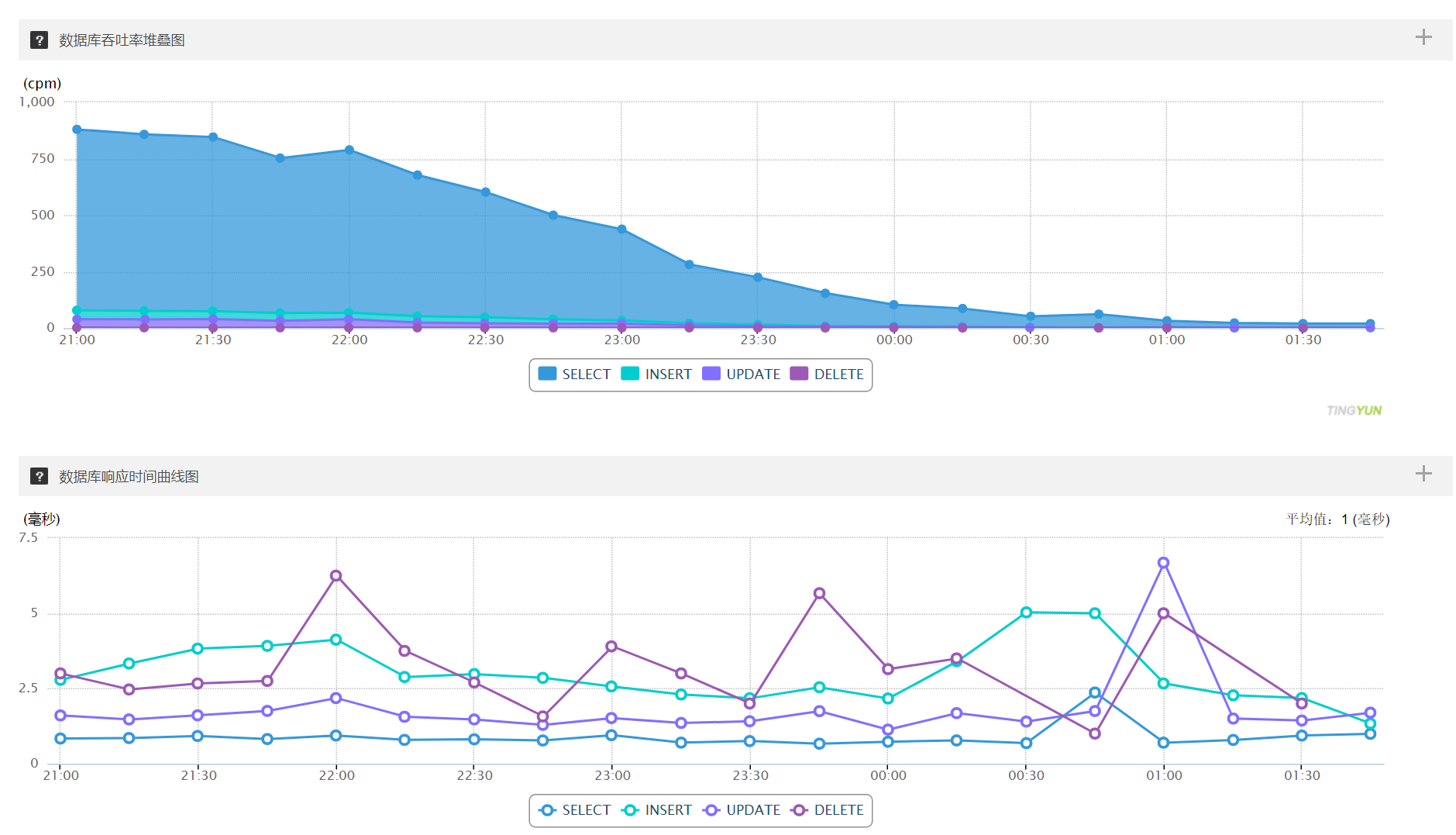
(b) 数据库分析
吞吐率、响应时间:压测期间、数据库吞吐率没有明显升高,应该是开启缓存的效果、且 RT 也都在 5 毫秒左右
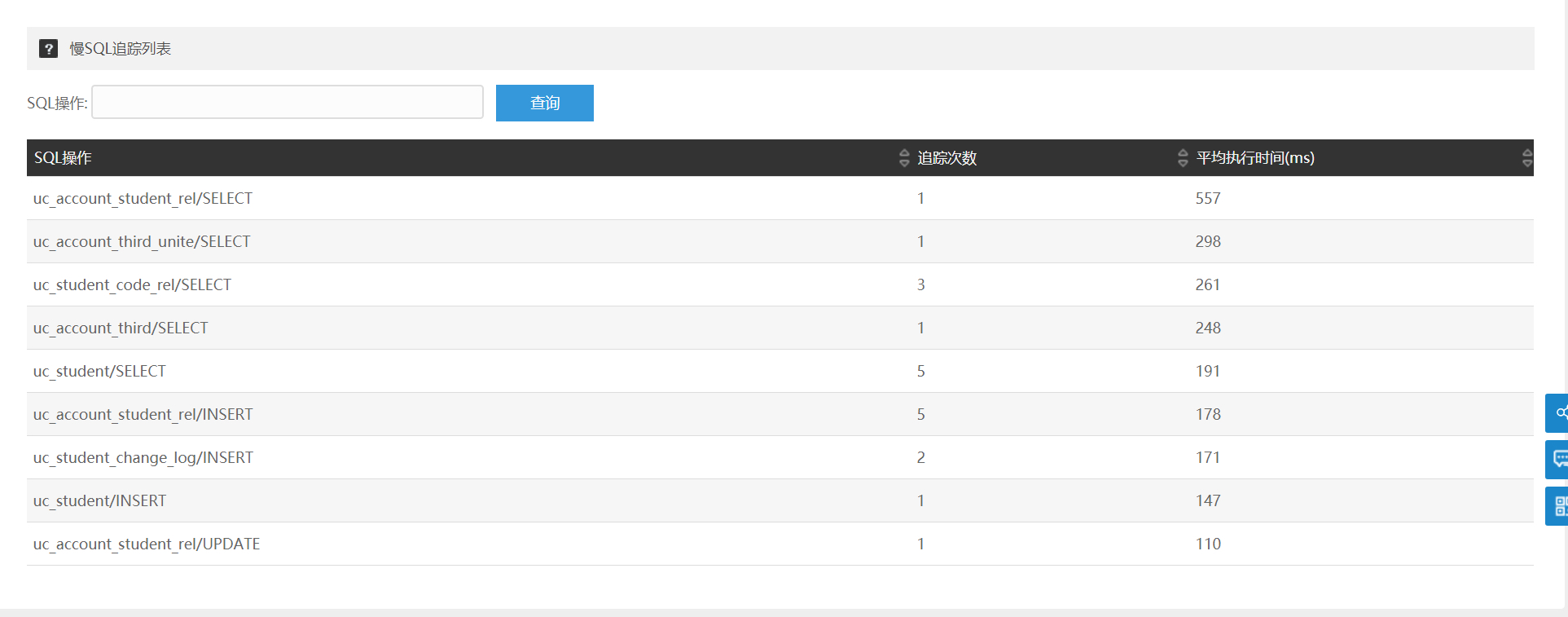
慢 SQL 追踪:次数、响应时间都不大
(c)Redis 分析
吞吐率、响应时间:压测期间吞吐率升高,说明流量都打到了 redis;响应时间最大值 373 毫秒、平均 RT 极小
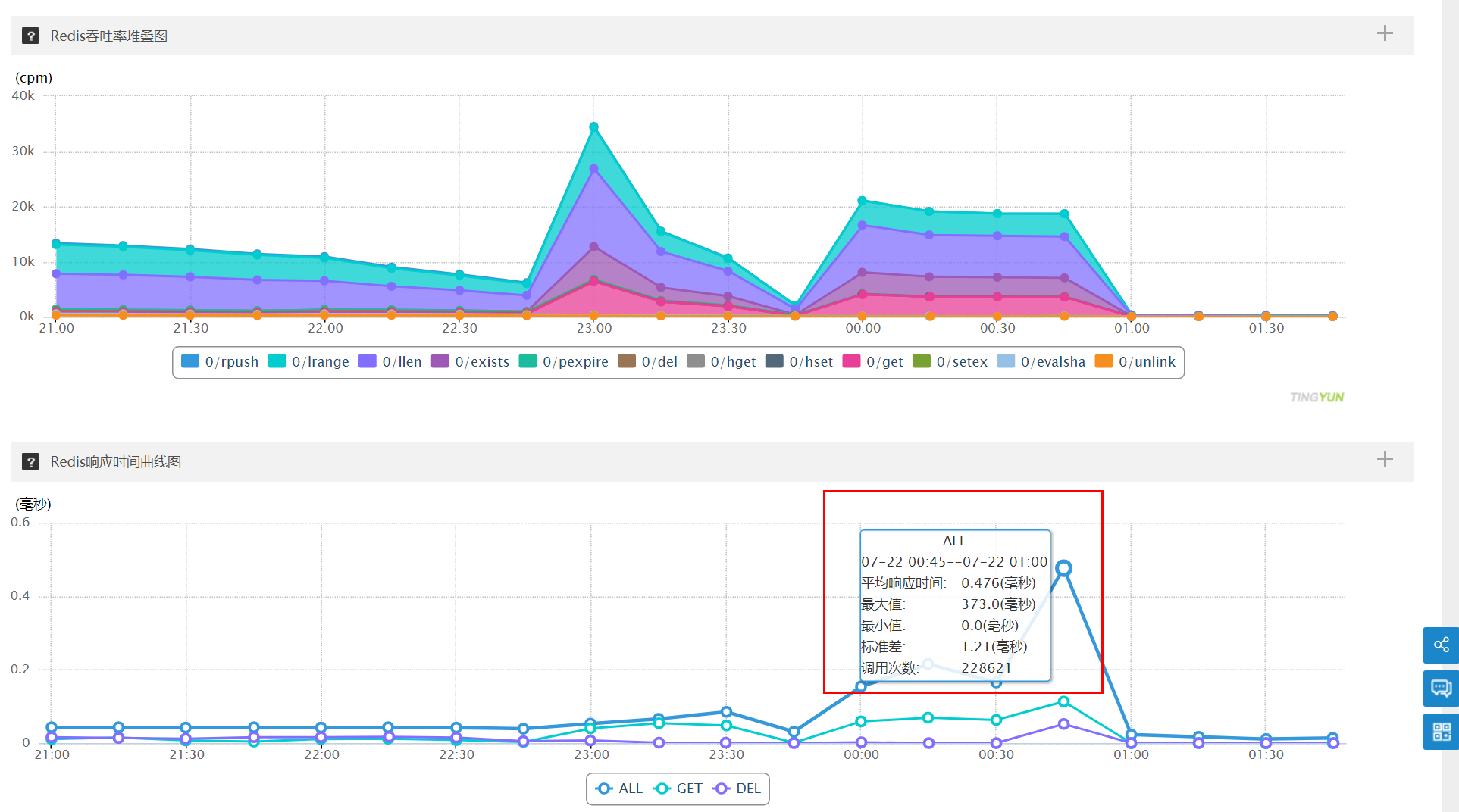
3.3.2 结论
数据库、Redis 非此次压测瓶颈,可以断定程序代码、线程池、JVM 参数、垃圾回收器等多方面有调优的可能性
3.4 代码、线程池、虚拟机层分析
3.4.1 异常统计分析
(a) 异常统计
压测期间异常信息总量:6840
压测期间异常信息总量 (6840) = RejectedExecutionException(6484) + Redis command timed out(212) + 其他异常 (空指针):144
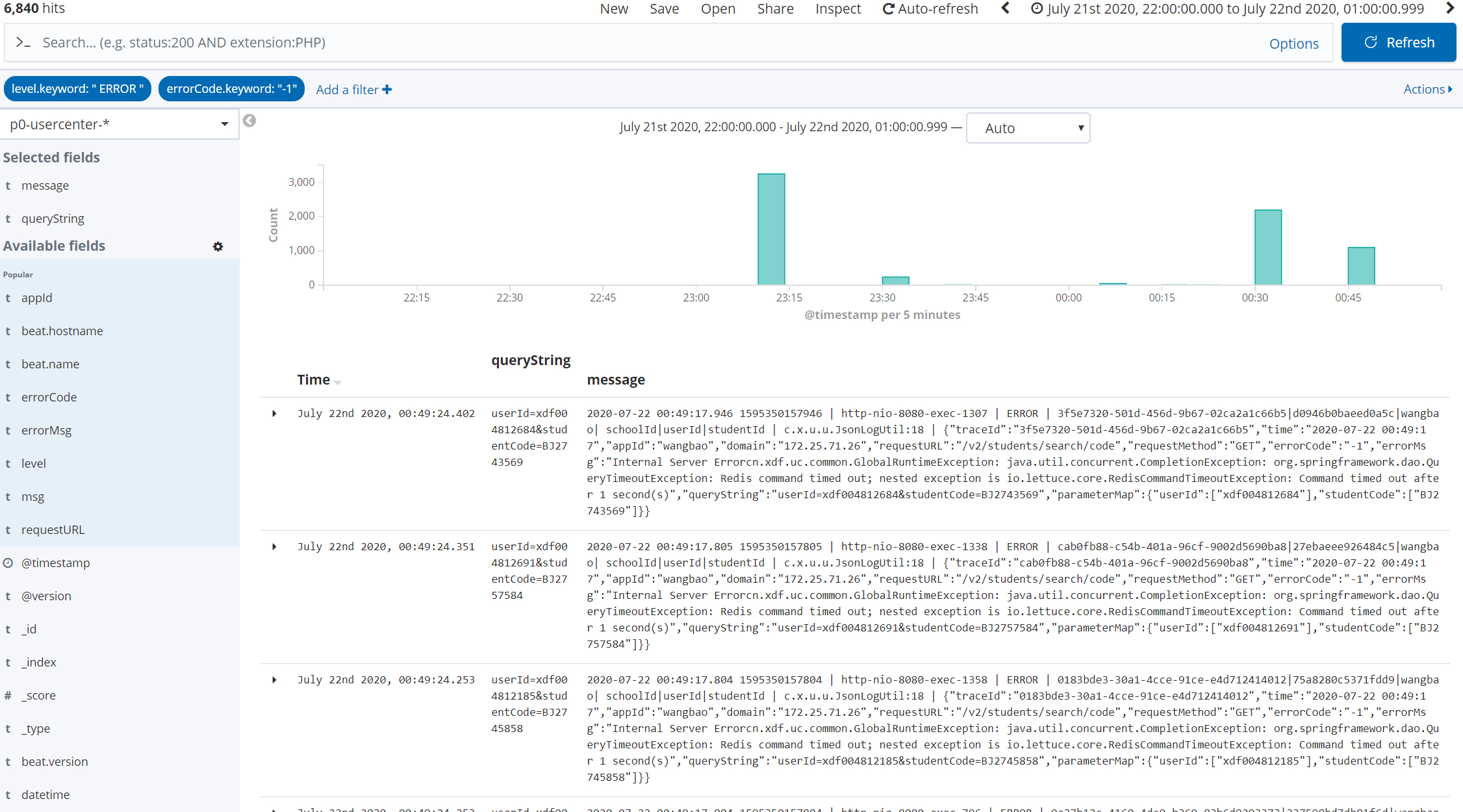
java.util.concurrent.RejectedExecutionException:6484 条
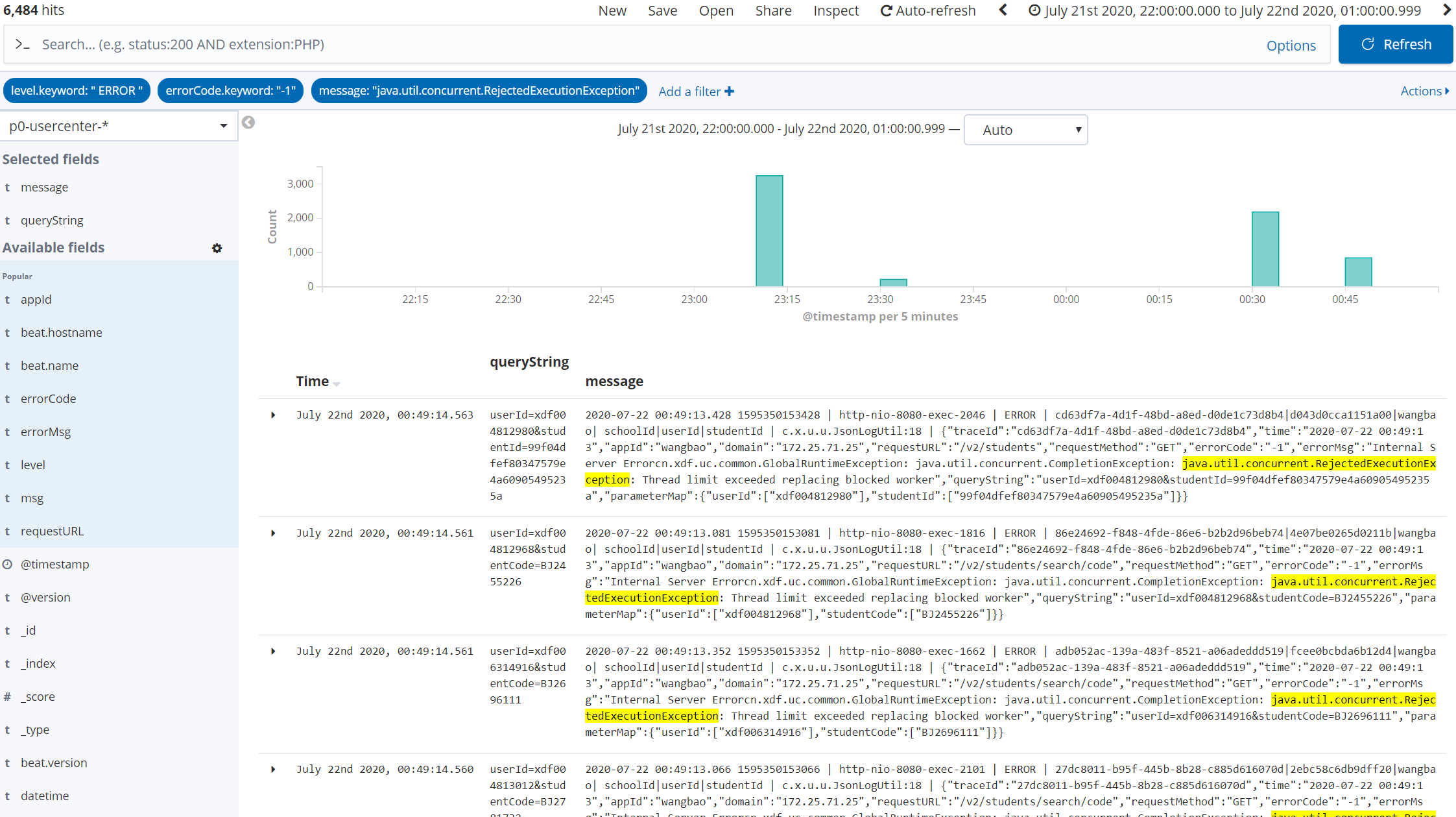
Redis command timed out:212 条
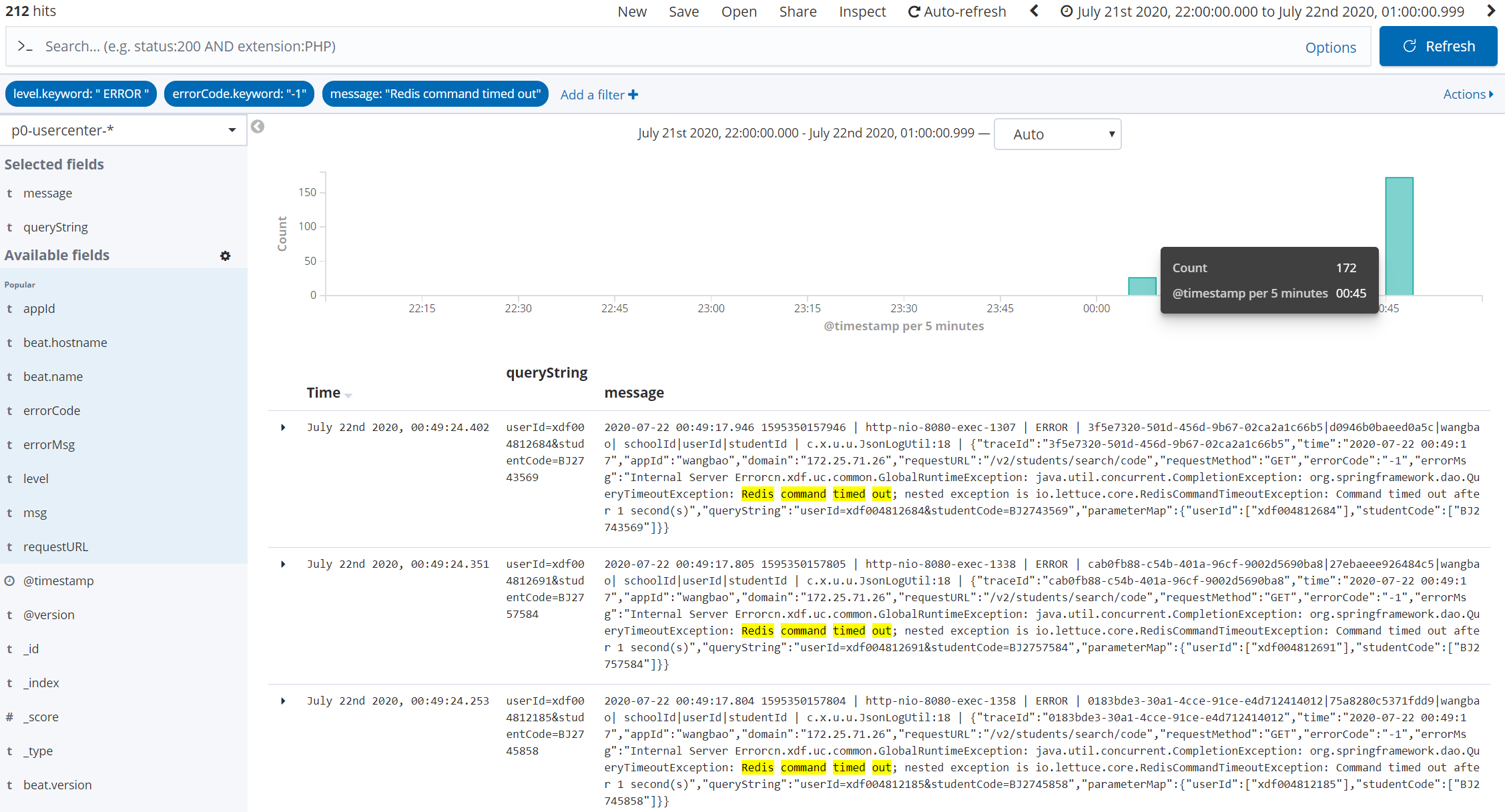
其他异常 (空指针):144
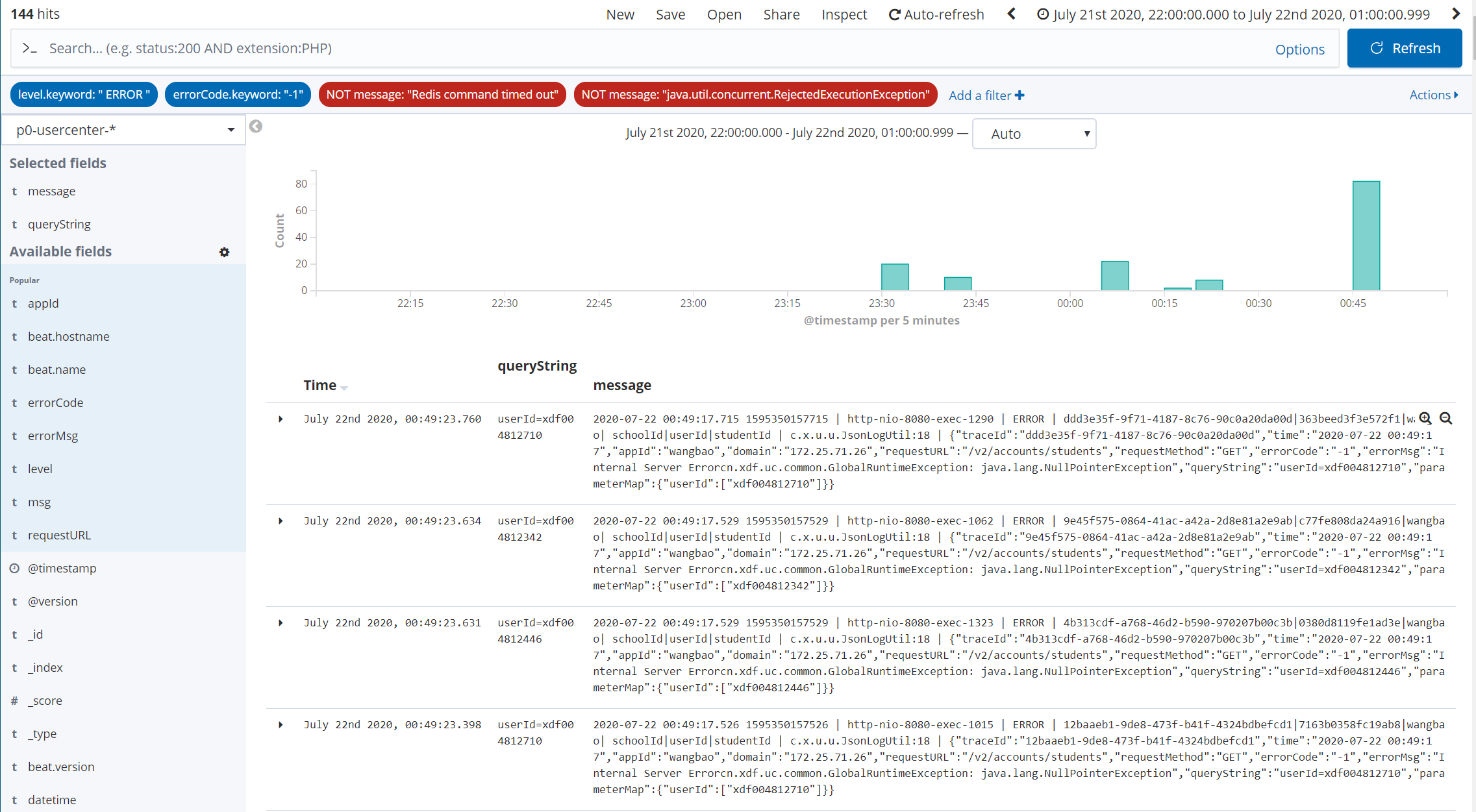
(b) 异常分析:
大部分异常为 java.util.concurrent.RejectedExecutionException,缓存改造中 C 端老师使用了【CompletableFuture】 + 【自定义线程池】方式,单台机器最大并发量为 queueSize2000 + maxSize500 = 2500,原来徐文老师仅仅使用了【CompletableFuture】方案,CompletableFuture 最大队里为 64M、线程数量为 cpu core - 1,最多会造成超时,但不会造成 RejectedExecutionException 异常,因为队列足够大 64M。
少部分异常为 Redis command timed out,可能是瞬间流量过大导致请求 redis 超时,也可能仅仅是自己程序内部线程竞争。
下面将从垃圾收集器选型、JVM 常用参数、线程数量、GC 耗时等几个方面分析
3.4.2 垃圾收集器
订单中心:CMS,适合做 web 应用等实时 api 服务,STW 时间短
用户中心:Java 默认的 Parallel,适合做任务,吞吐量优先,STW 时间长
3.4.3 JVM参数
订单中心:
-server -Xmx4g -Xms4g -Xmn512m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m -Xss256k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError -XX:CMSInitiatingOccupancyFraction=70
用户中心:
-Xmx8g -Xms8g
内存设置过大,使用默认配置 old/new=2,老年代 2*8/3、年轻代内存 8/3g,两者都过大,不利于内存回收,分布式应用应该采取小内存、多节点模式。
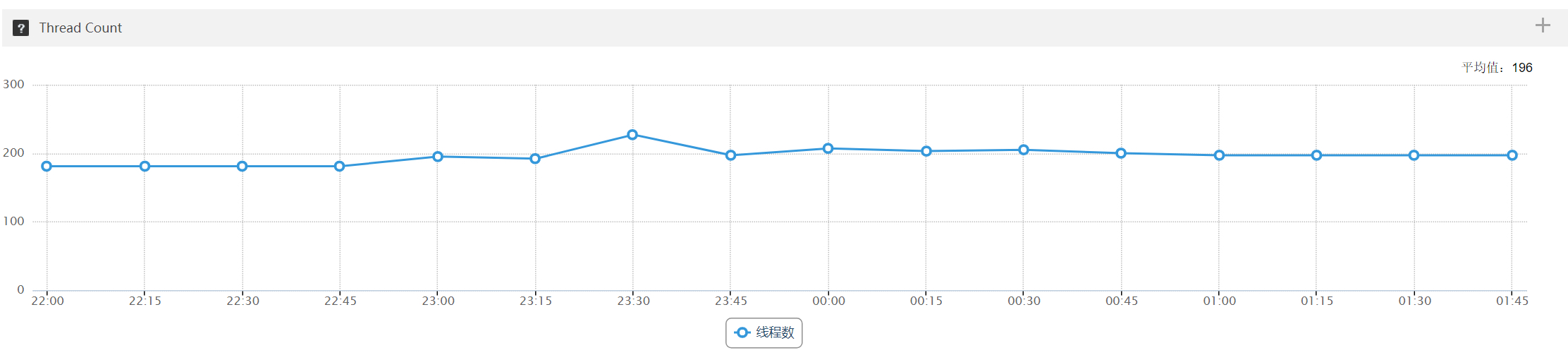
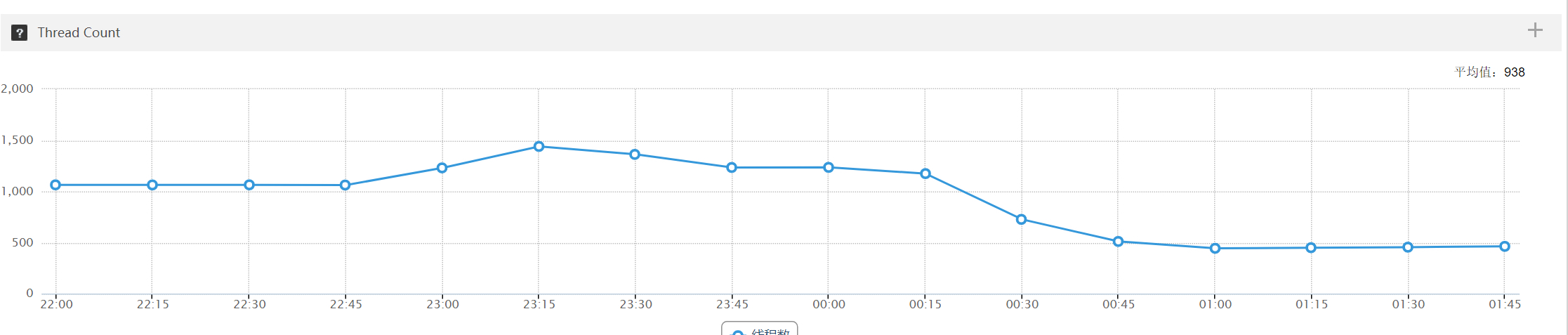
3.4.5 线程数量
用户中心是订单中心线程数量的 5-7 倍
订单中心:
用户中心:
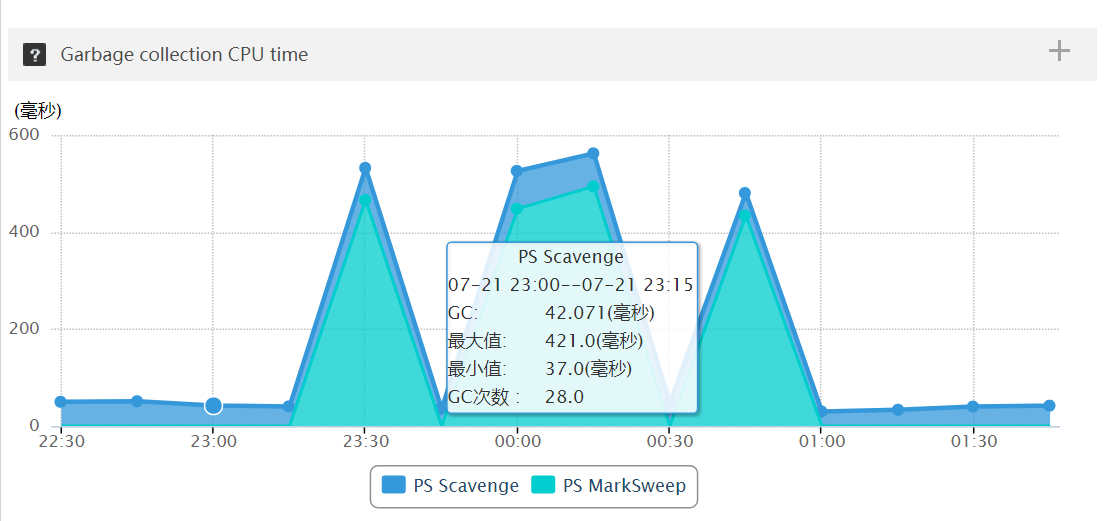
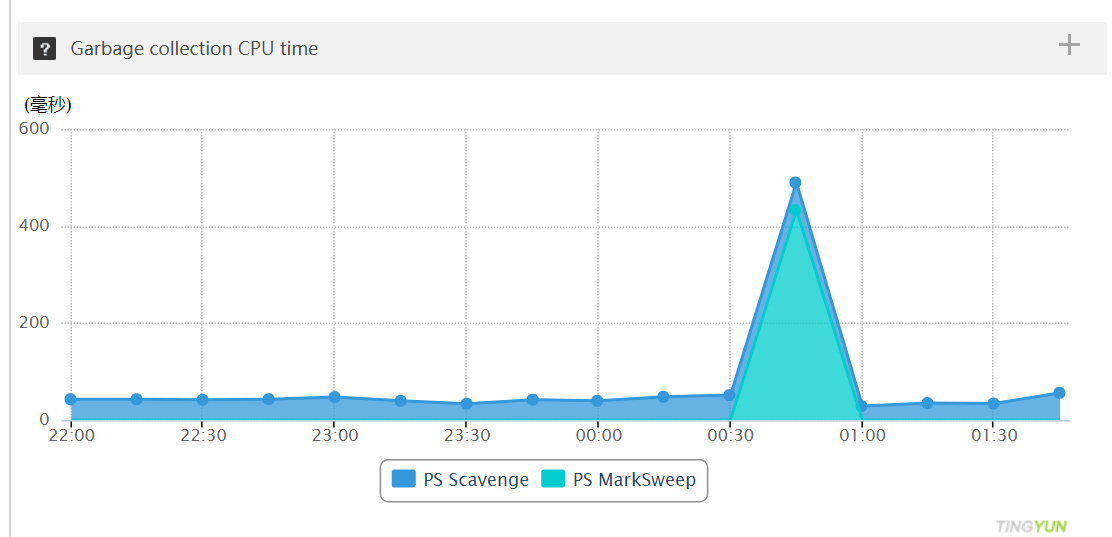
3.4.6 GC耗时
观察用户中心 6 台机器,在 23:30-01:00 之间出现几次 Full gc、数十次 Yong gc,STW 时间长达 600ms,两方面原因:线程数量过多、跟 gc 线程抢资源;堆内存设置过大导致 gc 时间过长
观察订单中心 3 台机器,在 23:30-01:00 之间只有 Yong gc,无 Full gc,且垃圾收集时间在 20ms 以内
订单中心
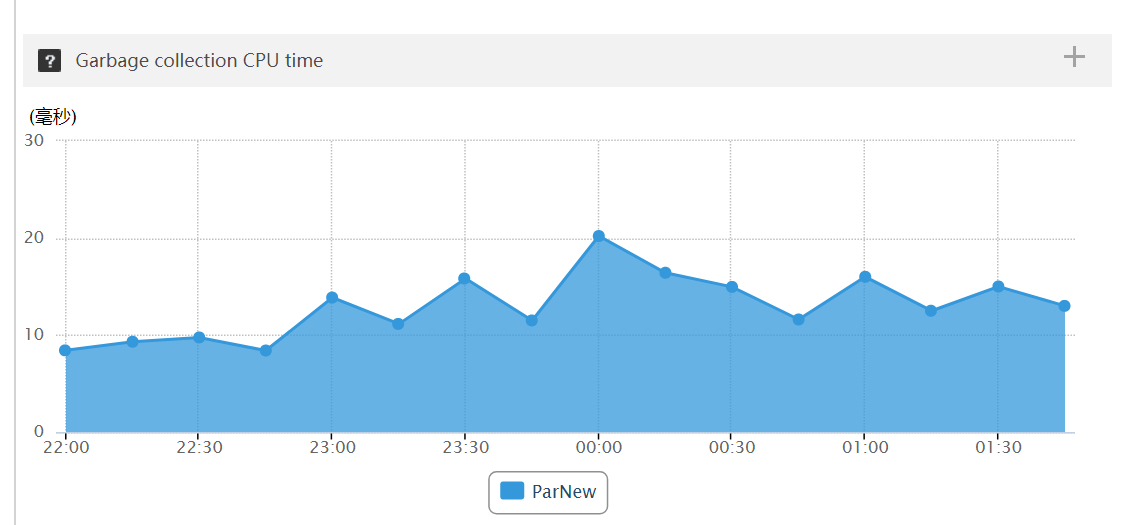
用户中心:
3.5 解决方案
3.5.1 线程池
原有方案:【CompletableFuture】+【自定义线程池】并发请求多张表组合数据
当流量较小时,1 个 tomcat 线程对应 N 个自定义线程请求组合,RT 较低;
当流量较大时,假如此时 1000 tomcat 线程,那内部需要 N*1000 个线程对应处理任务,当没有这么多线程时,需要进入队列等待,类似于异步处理任务,导致调用方等待超时;当达到自定义线程池上限时(队列满了,线程数量达到 maxSize),就会抛出 RejectedException
如果依然使用原有方案,因读写操作比例 10:1,则应该将写操作线程池aysncTaskExecutor、发送异步消息线程池TaskExecutorConfig,提交事务后刷新缓存线程池 transactionThreadTaskPool 都等写操作线程调小;将读操作改为缓存线程池 Executors.newCachedThreadPool()读取 (队列容量为 0),此线程池队列SynchronousQueue,缓存60秒,线程最大为数量为Integer.MAX_VALUE
A [blocking queue](eclipse-javadoc:☂=extend-core/D:\/Soft\/jdk1.8.0_92\/jre\/lib\/rt.jar in which each insert operation must wait for a corresponding remove operation by another thread, and vice versa. A synchronous queue does not have any internal capacity, not even a capacity of one.

依然会有 1 个请求对应 N 个线程的问题
建议方案:建议不再使用【CompletableFuture】 + 【自定义线程池】方式查询,直接使用 tomcat 主线程,串行请求单表数据(数据库或缓存)组合。
当流量较小时,此方案可能会导致单条 RT 升高,好处是不用切换线程,能够节省部分资源;
当流量较大时,也不会有明显的 RT 升高、有问题会直接抛出,而不是自定义线程池内部消化、且易维护。
3.5.2 垃圾收集器选型、JVM参数调整
建议使用 CMS 垃圾收集器,小内存(尤其是年轻代,因大部分都是很快消亡的,Yong gc 频繁点远远好于 Full gc)、多节点方案
-server -Xmx4g -Xms4g -Xmn512m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m -Xss256k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError -XX:CMSInitiatingOccupancyFraction=70
