

一、国内文字通用大模型现状
中国国内的 AIGC(生成式人工智能)市场正在快速崛起,吸引了科技公司、初创企业和资本的大量关注。以下是对中国 AIGC 大模型市场的详细介绍,包括主流公司、技术优势和劣势的对比。
市场发展阶段:
中国的 AIGC 市场起步于 2020 年左右,随着 OpenAI 发布 GPT 系列,中国公司加快了在大模型领域的投入。
2023 年后,大模型的商用化需求推动了更多企业进入这一领域,涵盖了生成文本、图像、音频和视频的技术。
政策支持:
政府大力推动人工智能发展,将其纳入“十四五”规划,并强调自主可控。
地方政府提供资金支持、算力补贴和场景应用推动。
应用场景:
文本生成:如智能客服、内容创作、教育。
图像生成:设计、影视、广告。
多模态生成:结合文本、音频和图像的综合应用。
主要公司及其特点
1. 百度 (Ernie Bot - 文心一言)
技术优势:
基于知识增强的生成技术,将百度多年的知识图谱数据(如百度百科)融入生成模型。
强大的多模态能力(文本、图像、视频生成)。
集成在百度的核心产品中,如搜索引擎、智能云服务。
市场表现:
已实现较好的商用落地,广泛应用于客户服务和企业生产力工具。
劣势:
主要依赖于中文场景,国际化不足。
模型创新性稍弱,追赶国际前沿有一定挑战。
2. 阿里巴巴 (通义千问)
技术优势:
提供通用领域与垂直领域相结合的大模型,例如金融、医疗、制造业等定制模型。
依托阿里云,具备极强的算力支持和客户生态。
优化了代码生成、自动化运维等企业级场景。
市场表现:
主攻 B 端市场,特别是在阿里云客户中落地迅速。
劣势:
偏重商业化,学术创新影响力相对较弱。
生态封闭性较强,外部合作有限。
3. 腾讯 (混元大模型)
技术优势:
强调技术中立性,面向开发者开放多种工具和 API 接口。
聚焦多模态生成和实时互动场景(如语音交互、游戏 AI)。
在社交、内容分发等自有场景中表现优异。
市场表现:
主要服务于腾讯自有生态(如微信、QQ)以及合作伙伴。
劣势:
外部生态较封闭,跨行业应用有限。
商业化规模和国际影响力尚待提升。
4. 华为 (盘古大模型)
技术优势:
突出自主可控,依托华为昇腾 AI 芯片提供高效算力。
在工业、医疗、农业等专业领域深耕,提供高度定制化解决方案。
以企业私有化部署为主,满足数据隐私要求。
市场表现:
聚焦于 B 端市场,已与政府机构和大型国企建立合作。
劣势:
在文本生成等通用领域稍弱。
商业模式单一,未广泛进入 C 端市场。
5. 创业公司与新兴玩家
商汤科技:多模态生成领先,特别是在图像、视频生成领域具备优势。
智谱 AI (Zhipu.AI):专注开源大模型,如 GLM 系列,吸引了开发者和科研机构。
MiniMax:聚焦对话生成和自然语言处理领域,灵活且创新性强。
优势:
灵活性高,能快速迭代产品。
注重开源,吸引开发者生态。
劣势:
资金和算力不足,面临大型科技公司挤压。
业务拓展受限,难以大规模商用。
二、国内视频大模型现状
1. 文生图(Text-to-Image Generation)
主要公司和技术特点
1.1 商汤科技 (SenseTime)
产品:商汤推出的 SenseAvatar、SenseMirage 等产品支持文生图生成,适用于设计、营销等场景。
技术特点:
多模态融合技术,基于自身的大规模视觉模型。
擅长高质量的图像生成和复杂场景合成,如人像、建筑、自然风景。
优势:在高分辨率图像生成方面具备优势,结合商汤的计算机视觉技术,生成效果自然。
劣势:训练数据以国内数据为主,在国际化表现上稍显不足。
1.2 字节跳动 (ByteDance)
产品:火山引擎推出了一系列 AI 生成工具,特别是在短视频创作和电商广告中应用文生图技术。
技术特点:
集成稳定扩散(Stable Diffusion)和深度生成技术,强调生成内容的真实性与美感。
在电商场景中自动生成背景和商品图像。
优势:依托抖音、今日头条等平台,在内容生态中快速落地。
劣势:更侧重于应用层创新,基础技术研发较弱。
1.3 京东 (JD)
产品:京东 AI 实验室开发的文生图工具,主要用于智能商品设计和电商内容生成。
技术特点:
聚焦于商品设计场景,如智能生成产品广告图、推荐图片等。
强调风格迁移与产品图像优化。
优势:数据贴近实际业务场景,模型实用性强。
劣势:在艺术风格生成上较弱,场景局限于电商领域。
优势与应用场景
优势:
中国有丰富的中文描述与图像配对数据,便于模型训练。
文生图技术在广告、电商、游戏设计中需求旺盛。
应用场景:
营销和广告创意生成。
游戏原画设计、影视概念图绘制。
个性化社交媒体内容生产。
2. 文生视频(Text-to-Video Generation)
主要公司和技术特点
2.1 百度 (Baidu)
产品:文心一言的多模态版本支持文生视频生成,用于企业宣传视频和短视频制作。
技术特点:
在多模态基础上融合视频合成技术。
通过文字描述生成动态画面,如天气变化、简单动画。
优势:生成速度快,适合短视频场景,已经在百度智能云中落地应用。
劣势:生成视频的细节和复杂场景能力较弱。
2.2 阿里巴巴 (Alibaba)
产品:通义千问集成了文生视频模块,主要服务于直播、教育等领域。
技术特点:
强调内容的时间逻辑和动态性,适合生成教育视频和广告素材。
在视频中加入品牌元素和动态字幕。
优势:可结合阿里云为企业提供定制化服务。
劣势:内容创新性有待提升,局限于较简单的视频生成。
2.3 微软亚洲研究院 (Microsoft Research Asia)
合作伙伴:与国内高校和企业合作,推出的文生视频模型可生成具有电影感的短片。
技术特点:
强调视频生成的风格化和情感表达。
跨模态生成技术,包括声音、字幕与画面同步生成。
优势:在学术界影响力强,生成视频质量高。
劣势:产业化不足,实际应用场景有限。
优势与应用场景
优势:
拥有强大的多模态数据和先进的视频处理技术。
商业化场景丰富,如教育、广告、短视频制作。
应用场景:
动态广告素材制作。
个性化教育内容生成。
娱乐行业的视频故事创作。
3. 视频生成视频(Video-to-Video Generation)
主要公司和技术特点
3.1 商汤科技 (SenseTime)
产品:提供视频风格迁移与内容增强技术,适合短视频内容创作。
技术特点:
支持将普通视频转换为动画风格、复古风格等。
强调视频质量提升,包括分辨率增强和色彩优化。
优势:技术成熟度高,在影视后期制作和短视频优化中表现优异。
劣势:功能更偏向辅助编辑,完全生成能力较弱。
3.2 快手 (Kuaishou)
产品:快手 AI 实验室开发的视频生成工具,可将用户普通视频转换为炫酷特效视频。
技术特点:
聚焦于短视频特效生成与背景替换。
提供个性化模板,适合普通用户快速生成创意视频。
优势:贴近用户需求,易用性强,效果突出。
劣势:更侧重于 C 端用户,技术深度稍弱。
3.3 腾讯 (Tencent)
产品:腾讯云推出的视频生成服务,适用于广告制作和游戏视频内容。
技术特点:
强调视频内容的逻辑性与连贯性。
支持通过已有视频生成补充内容(如过场动画)。
优势:结合游戏和社交场景,生成效果自然。
劣势:在大规模生产视频内容方面仍有待提升。
优势与应用场景
优势:
中国短视频行业发展迅猛,推动视频生成需求快速增长。
视频生成技术应用门槛较低,容易被普通用户接受。
应用场景:
短视频特效制作。
游戏过场动画生成。
视频质量提升与后期优化。
总结对比
三、国外视频大模型
3.1、文字生成大模型(Large Language Models for Text Generation)
主要公司与技术特点
1. OpenAI
产品:GPT 系列(最新为 GPT-4 Turbo)。
技术特点:
支持多语言理解与生成,掌握复杂推理、编码和创意内容生成能力。
微调能力强,能够适配不同的行业需求(如医疗、法律、教育等)。
引入图像和文本多模态能力,扩展了生成范围。
优势:
拥有最大规模的训练数据和最强大的推理能力。
开发者社区活跃,生态支持全面。
劣势:
商业化门槛较高,企业使用成本高昂。
模型黑箱性较强,缺乏透明度。
2. Google DeepMind
产品:Gemini 系列(取代原 Bard 项目)。
技术特点:
整合 Google 搜索数据,提供更实时的知识更新能力。
支持多模态生成(文本 + 图像 + 代码等)。
强调语义理解与逻辑推理,适合复杂场景。
优势:
依托 Google 的海量数据与强大算力,训练模型效果优异。
与搜索引擎深度整合,实时性强。
劣势:
在创意生成领域表现稍逊,生成内容有时趋于保守。
3. Anthropic
产品:Claude 系列(最新版本 Claude 4)。
技术特点:
以“可控性”和“安全性”为核心,强调模型的可解释性。
支持长文本生成,能够处理上百万字的上下文。
优势:
更适合高敏感度场景(如法律、金融)和安全性需求高的行业。
长文档生成能力领先。
劣势:
数据规模和生成创新性略逊于 OpenAI 和 Google。
4. Meta
产品:Llama 系列(最新版本 Llama 3)。
技术特点:
开源策略,强调灵活性和社区合作。
专注于高效的模型架构,提升模型训练速度和运行效率。
优势:
开源模型在科研和开发者社区中获得广泛支持。
更适合中小型企业和研究机构的定制化需求。
劣势:
在通用性和生成质量上稍逊于 GPT 和 Gemini。
优势与应用场景
优势:
支持多行业、多语言、多任务,适用范围广。
模型推理能力强,生成内容质量高。
应用场景:
内容创作(文章、报告、脚本)。
客户支持和问答系统。
编码辅助和代码生成。
3.2、视频生成大模型(Video Generation Models)
1. Runway
产品:Gen-2 系列(文本生视频、视频生视频)。
技术特点:
支持从文本描述生成动态视频。
强调视频的艺术感和风格化,适用于创意场景。
视频生视频支持视频内容的风格迁移和高分辨率优化。
优势:
界面友好,适合创作者和设计师。
生成视频的艺术性较高,内容创意丰富。
劣势:
生成内容的逻辑性和真实感稍弱,适合短视频和动画场景。
2. NVIDIA
产品:Video Diffusion、Omniverse 工具链。
技术特点:
基于扩散模型,生成具有高时间逻辑的视频内容。
结合物理模拟和 3D 渲染技术,可生成工业级视频内容。
优势:
生成视频质量高,适合工业、影视后期和游戏开发。
可与 NVIDIA GPU 硬件深度整合,效率高。
劣势:
商业化应用门槛较高,对硬件要求苛刻。
3. Google DeepMind
产品:Imagen Video。
技术特点:
强调高分辨率视频生成,支持复杂动态场景。
结合文本描述生成符合逻辑的时间序列内容。
优势:
视频生成的连贯性与真实性较强,适合专业影视制作。
视频生成中的物体动态处理表现优异。
劣势:
生成速度较慢,模型复杂度高。
4. Meta
产品:Make-A-Video。
技术特点:
基于生成对抗网络(GAN),支持短视频生成与风格化处理。
适合生成卡通化、艺术化和创意性强的内容。
优势:
生成内容独特,适合社交媒体创意应用。
开源策略,便于开发者进行二次开发。
劣势:
对复杂时间逻辑的处理能力不够,生成场景受限。
优势与应用场景
优势:
国外模型技术多样,既有扩散模型(Diffusion Models)也有 GAN,适应多种生成需求。
视频生成技术从文本到动态画面的生成逻辑更加完善。
应用场景:
影视后期制作和特效生成。
动态广告创意生成。
短视频和社交媒体内容创作。
3.3、文字与视频模型的对比
四、其他国外文生图、文生视频和视频生成大模型介绍
1. Pika Labs
定位:文生视频生成工具
技术特点:
使用文本描述生成视频内容,支持高动态场景和艺术风格的视频。
强调简单易用,用户可以通过自然语言控制视频生成。
支持短视频的多帧生成和风格迁移。
优势:
生成速度快,适合创作者快速制作视频内容。
界面简洁,非技术用户也能快速上手。
劣势:
生成的视频长度有限,适合短视频而非长片。
视频的逻辑性和高保真性稍弱。
应用场景:
社交媒体内容创作、广告短片和创意表达。
2. Kling AI
定位:全栈多模态 AI 平台
技术特点:
提供从文本生成图像、视频到多模态交互的解决方案。
采用扩散模型和多模态融合技术,能够生成符合上下文的高质量内容。
支持 API 接入和定制化开发,适用于不同企业场景。
优势:
技术方案灵活,适配性强,支持企业级大规模生成需求。
多模态集成效果好,生成结果更契合业务需求。
劣势:
相较于垂直领域工具,用户上手成本略高。
应用场景:
电商平台的产品内容生成、影视创意内容创作、品牌营销。
3. Luma AI
定位:三维生成与视频生成平台
技术特点:
专注于 3D 建模和场景生成,支持从文本描述生成复杂的 3D 模型。
结合视频生成技术,可从视频素材中提取 3D 场景或生成动态 3D 内容。
使用 NeRF(神经辐射场)技术,高度还原场景光影和细节。
优势:
在 3D 场景建模和渲染领域表现出色,生成效果高度逼真。
广泛应用于游戏开发、虚拟现实和电影制作。
劣势:
模型生成速度较慢,对硬件性能要求较高。
应用场景:
游戏行业中的虚拟场景生成、影视特效中的虚拟拍摄、VR/AR 应用开发。
4. PixAI
定位:开源 AIGC 平台
技术特点:
提供文本生成图像、文生视频等功能,专注于艺术创作和风格化生成。
支持用户定制化风格训练和模型微调,增强模型的特定领域表现。
开放 API 接口,开发者可以轻松集成到不同应用中。
优势:
开源策略,用户可以直接访问和定制模型。
生成内容风格化强,适合创意设计和艺术领域。
劣势:
商业化应用支持有限,缺乏大规模生产能力的企业支持。
应用场景:
数字艺术创作、游戏角色设计、动画和卡通风格视频。
五、对比分析
总结
国外在文生图、文生视频和视频生成方面的技术发展呈现多样化和专业化趋势。从用户友好的创作工具(如 Pika Labs)到高度定制化和技术密集的平台(如 Luma AI 和 Kling AI),每种技术都针对不同的应用场景进行了优化。这些平台的共同点是强调生成质量和用户体验,同时在商业化路径上也各有侧重。
五、聚合享效率工具-兔程灵犀
兔程互联科技,经调研由国内互联网大厂下的几个有志合伙创建,只基于现有国内外 AIGC 大模型能力,提供可想象的商业化产品,目前旗下有:灵犀小只 和 笔头写作 两大产品。
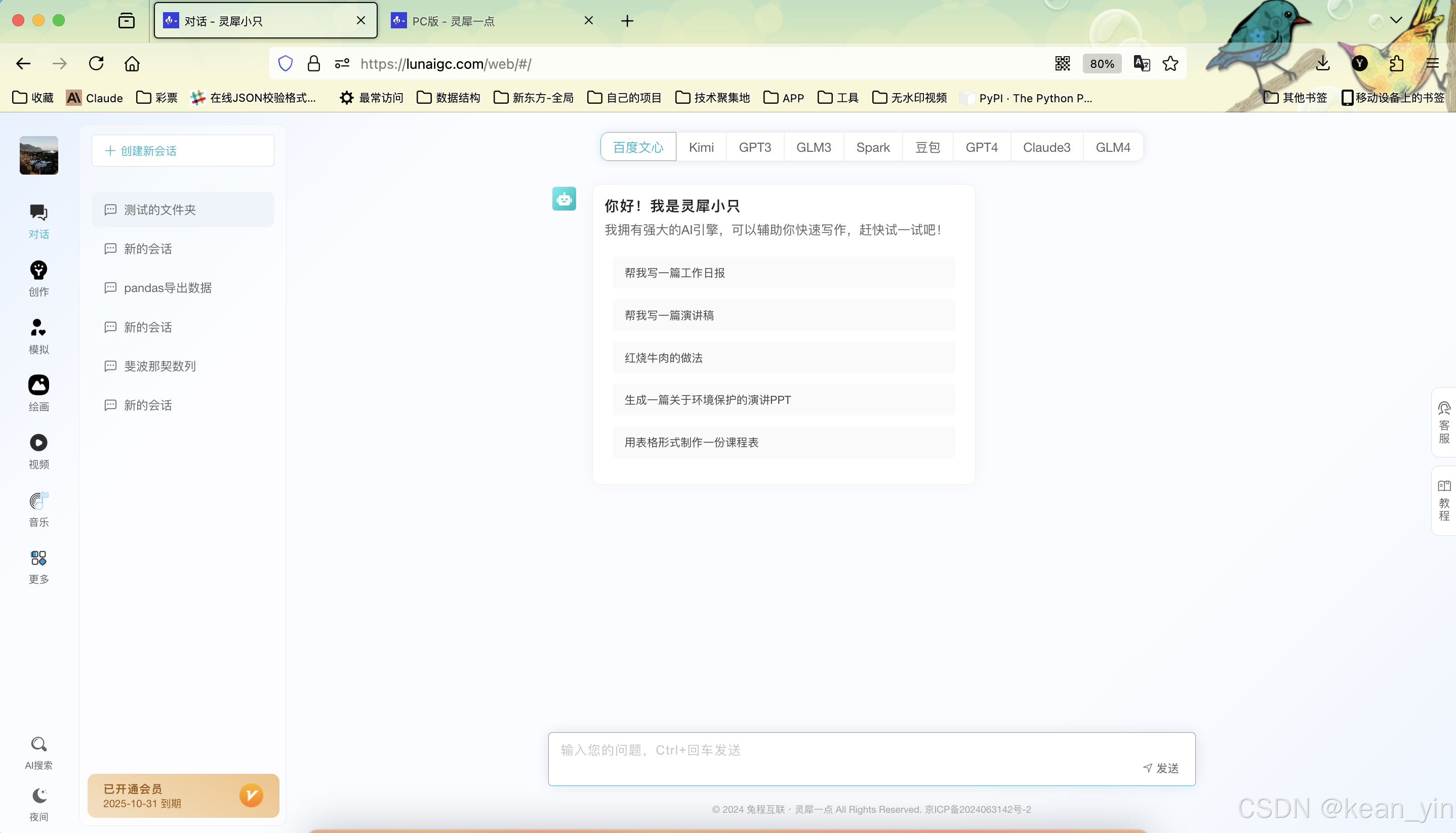
1 灵犀小只
从主页可以看见兔程灵犀其实有很多模块,诸如:文字,绘画,视频,音乐,思维导图和 AI 搜索等板块。
1.1 通用聚合文字大模型
国内初创公司遍地开花,想要跻身其中必定很难,灵犀目前是将市场上现有的 AI 产品进行打包聚合在一起,从文字大模型页可以看见目前已经对接了如文心、Kimi、GPT、Spark、豆包、Claude、和 GLM。相信他们还会对接下去。致于为什么做聚合,我想应该是方便大家在一个平台下就能享受全部的 AI 体验吧。

1.2 绘图能力
从灵犀绘图使用上看,当前绘图应该是对接的 Midjourney,使用上其实还是很方便的,你只需要想象,选择你想要的内容就可以生成,因为他们提供了 Prompt 工具方便一键使用
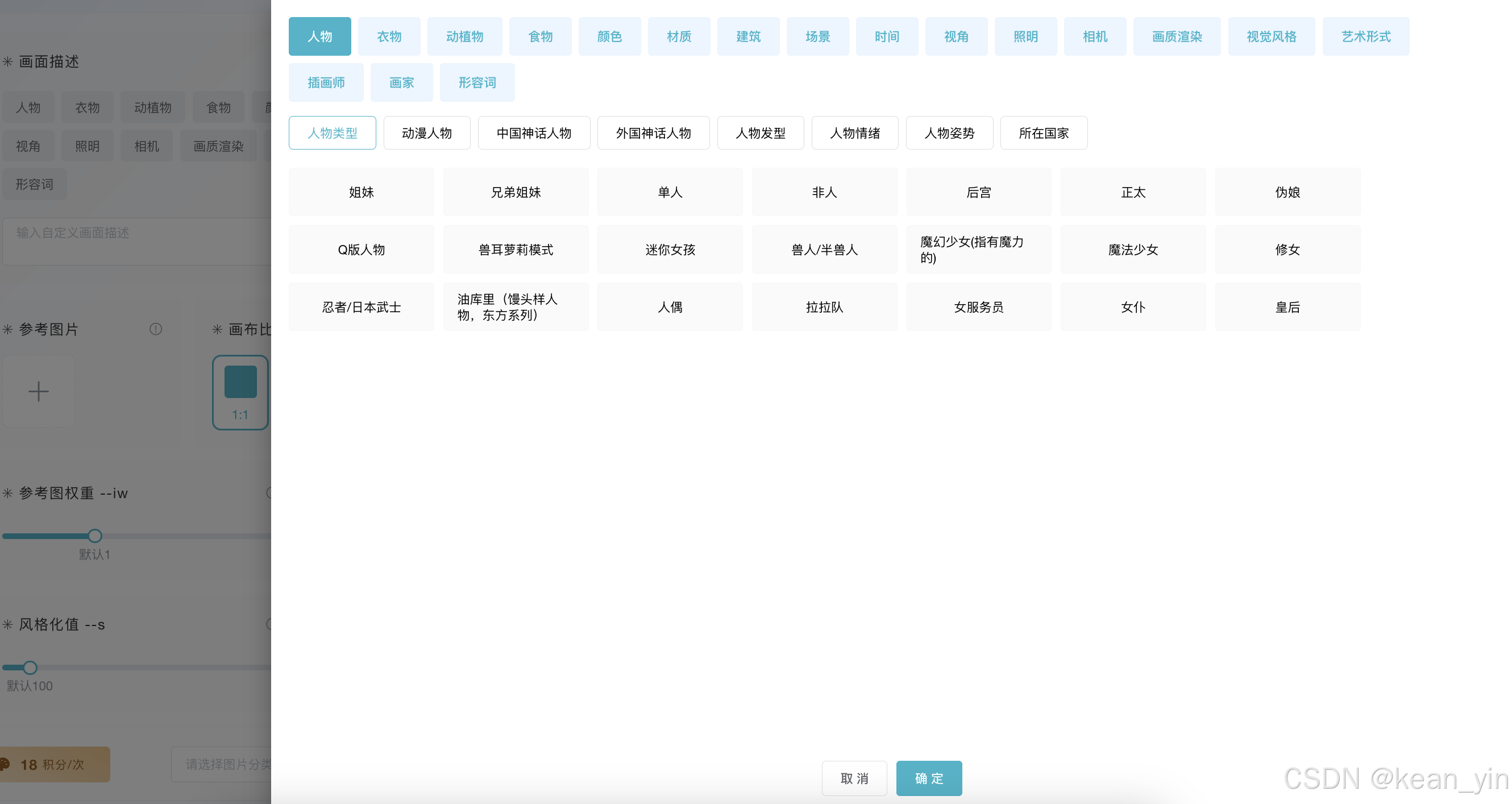
同时有很多细致参数控制,加入提示词如
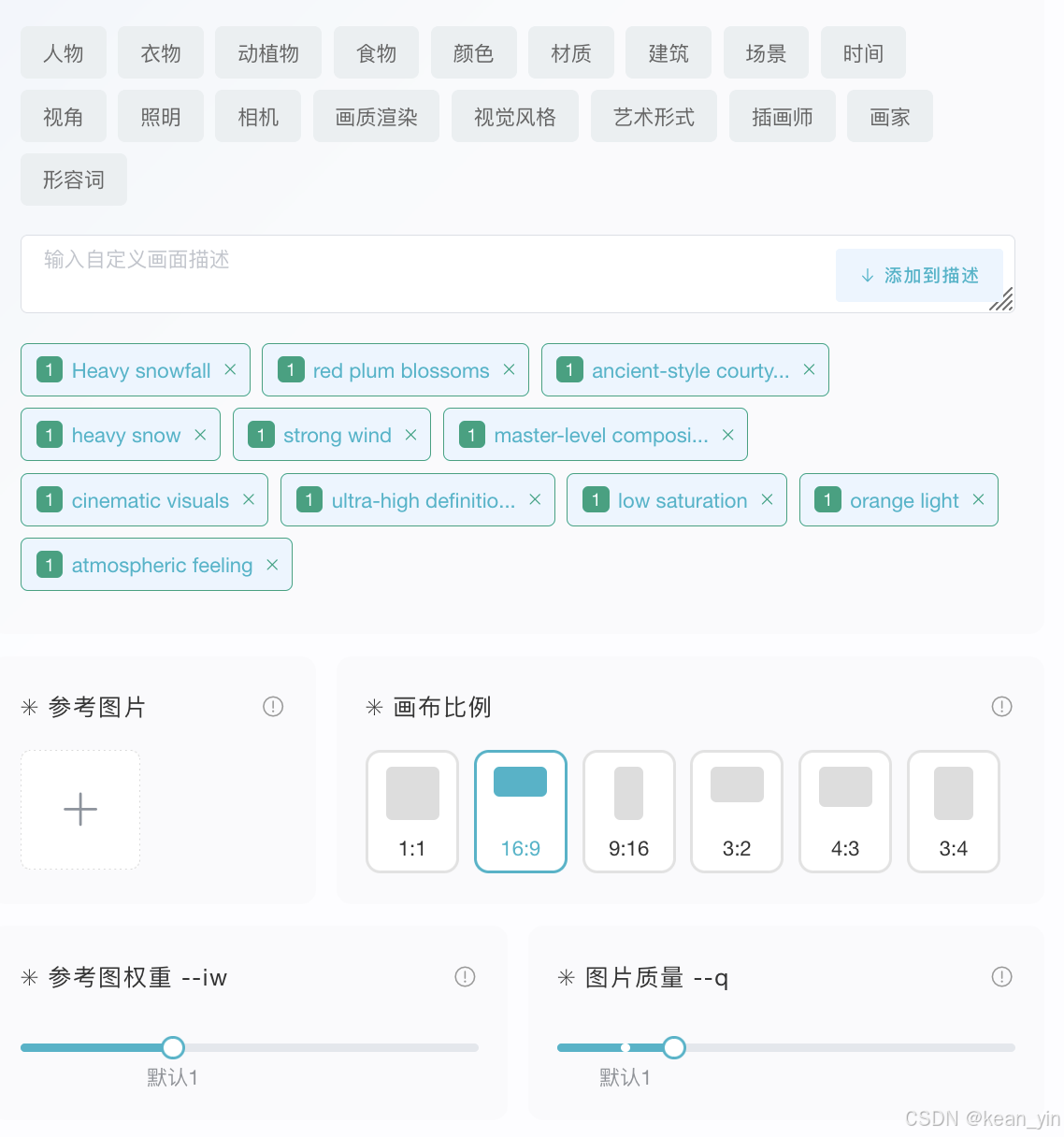
便可以提交的任务。 同时还可以针对生成好的某一个图片继续演变和扩大(唯一就是这个攻功能智能在 PC 端可以体验)继续进行图片创作





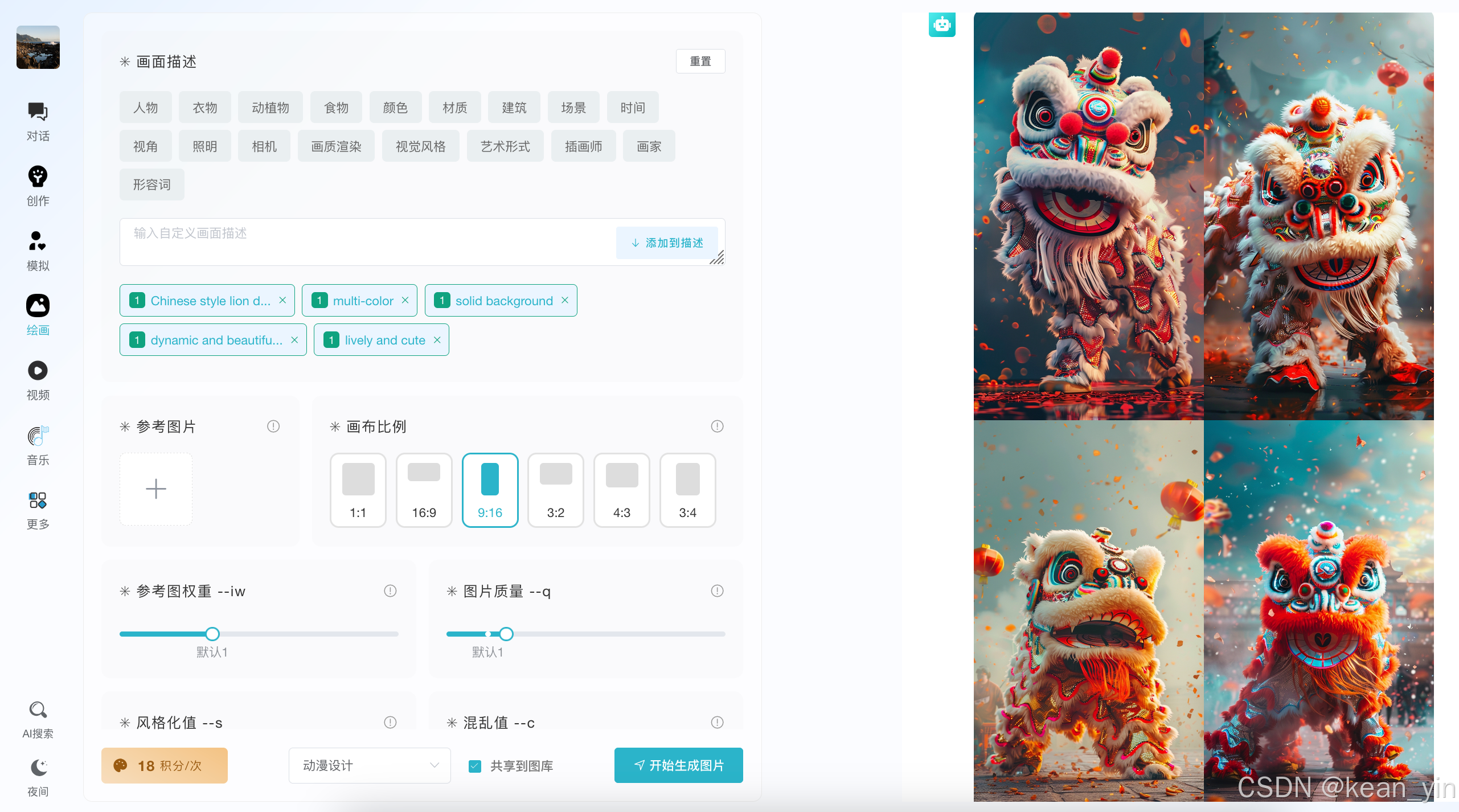
1.3 视频生成
视频生成板块目前支持 Pika 和 Runway
使用也很简单,填入提示词生成即可
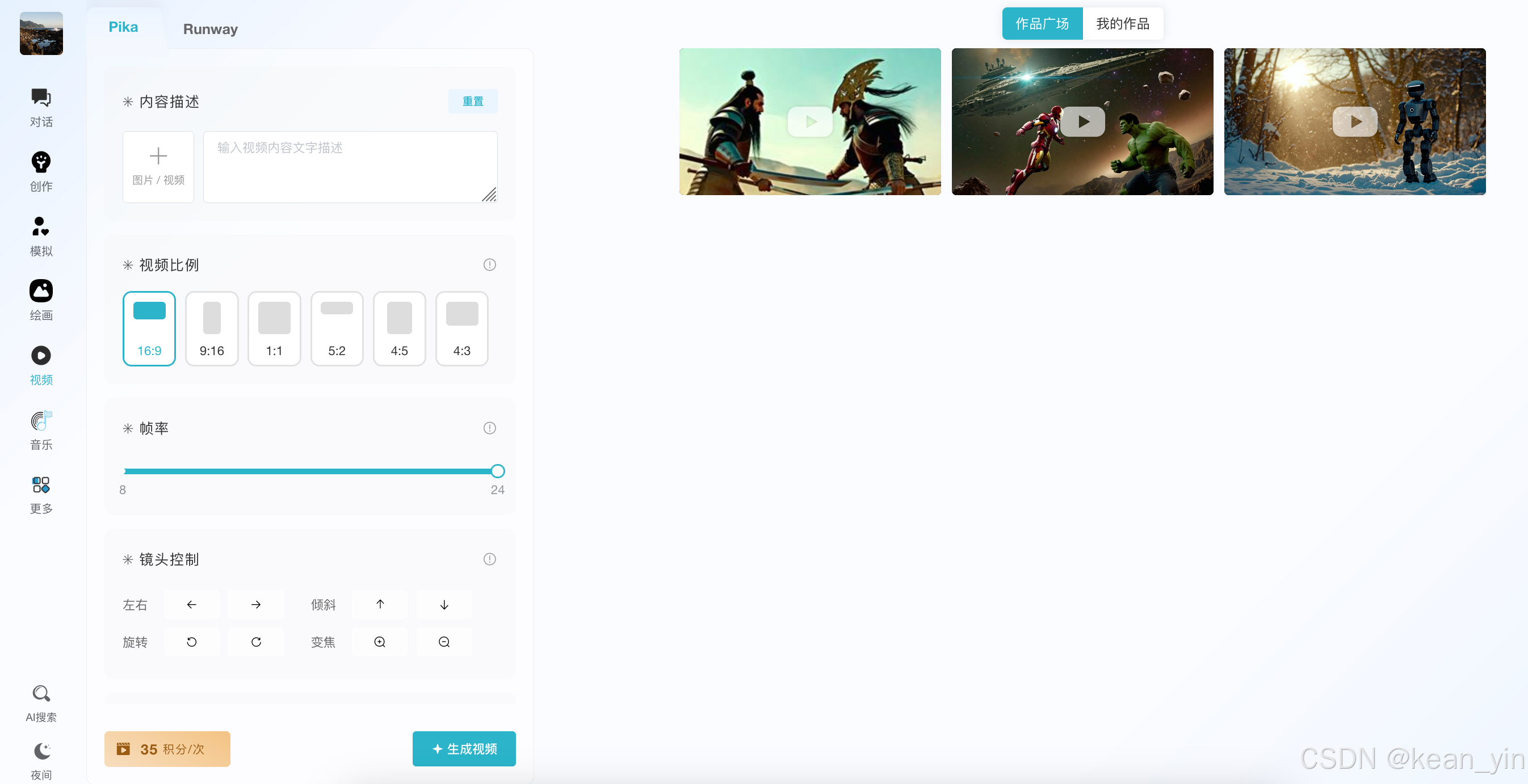
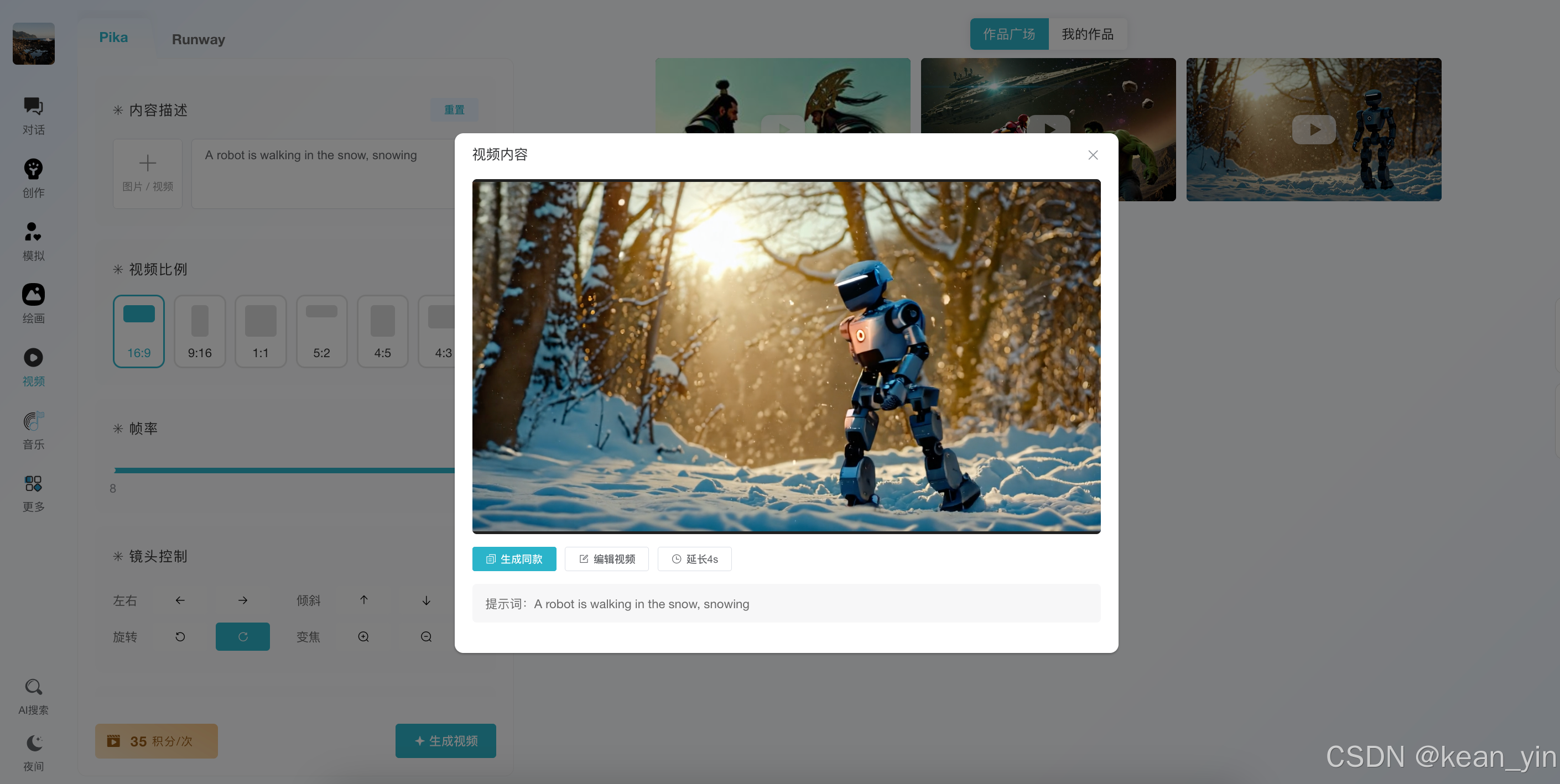
音乐板块类似。 其他板块请各位自行去体验吧,写稿写的手累 哈哈哈哈
2 兔程互联-笔头写作
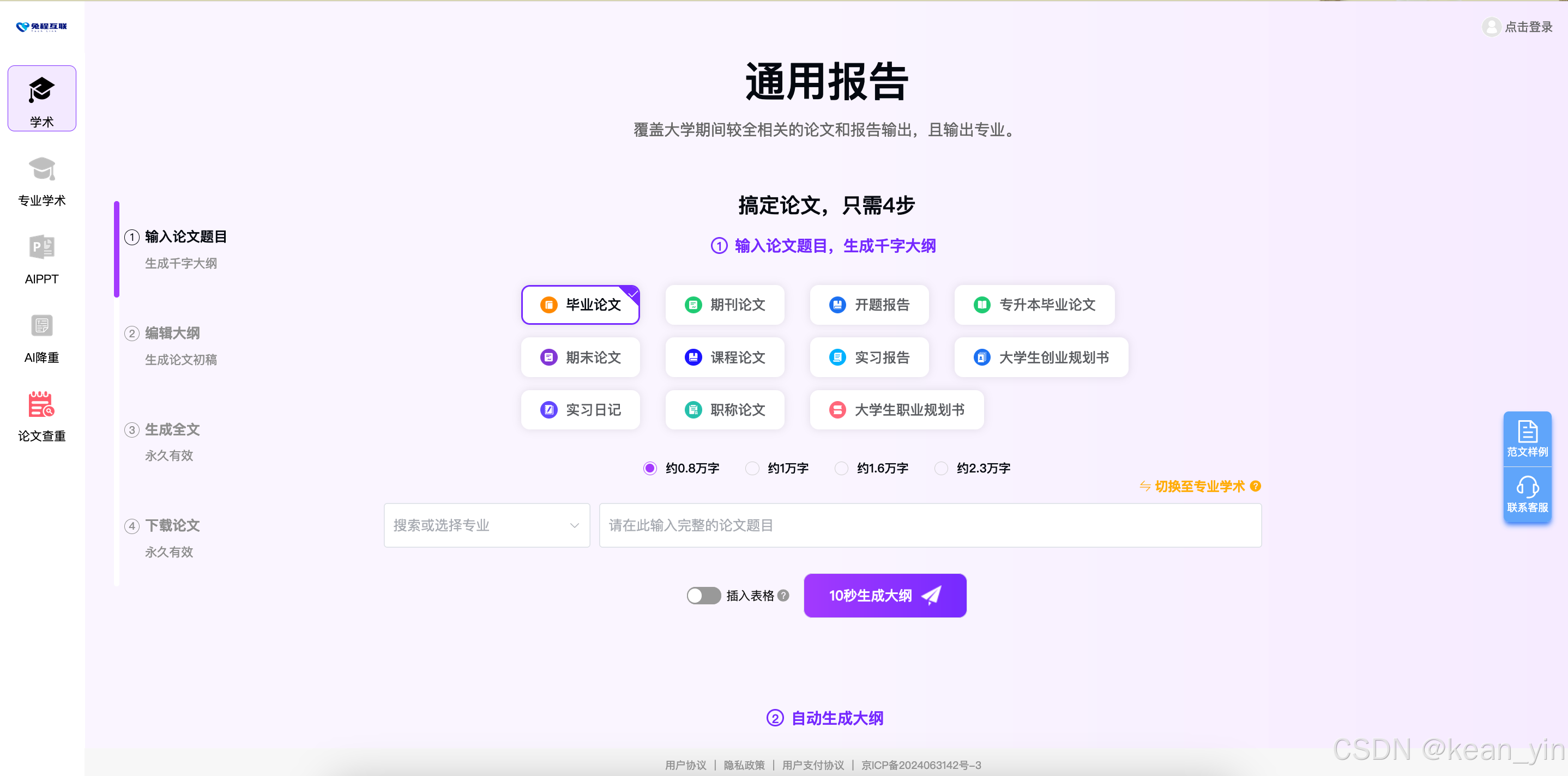
笔头目前涵盖职高大学和其他相关论文和报告,普通学术和专业学术论文生成。 同时还有 AIPPT 创作和 AI 论文片段降重和整片论文查重。
2.2.1 选择或填写论文相关信息
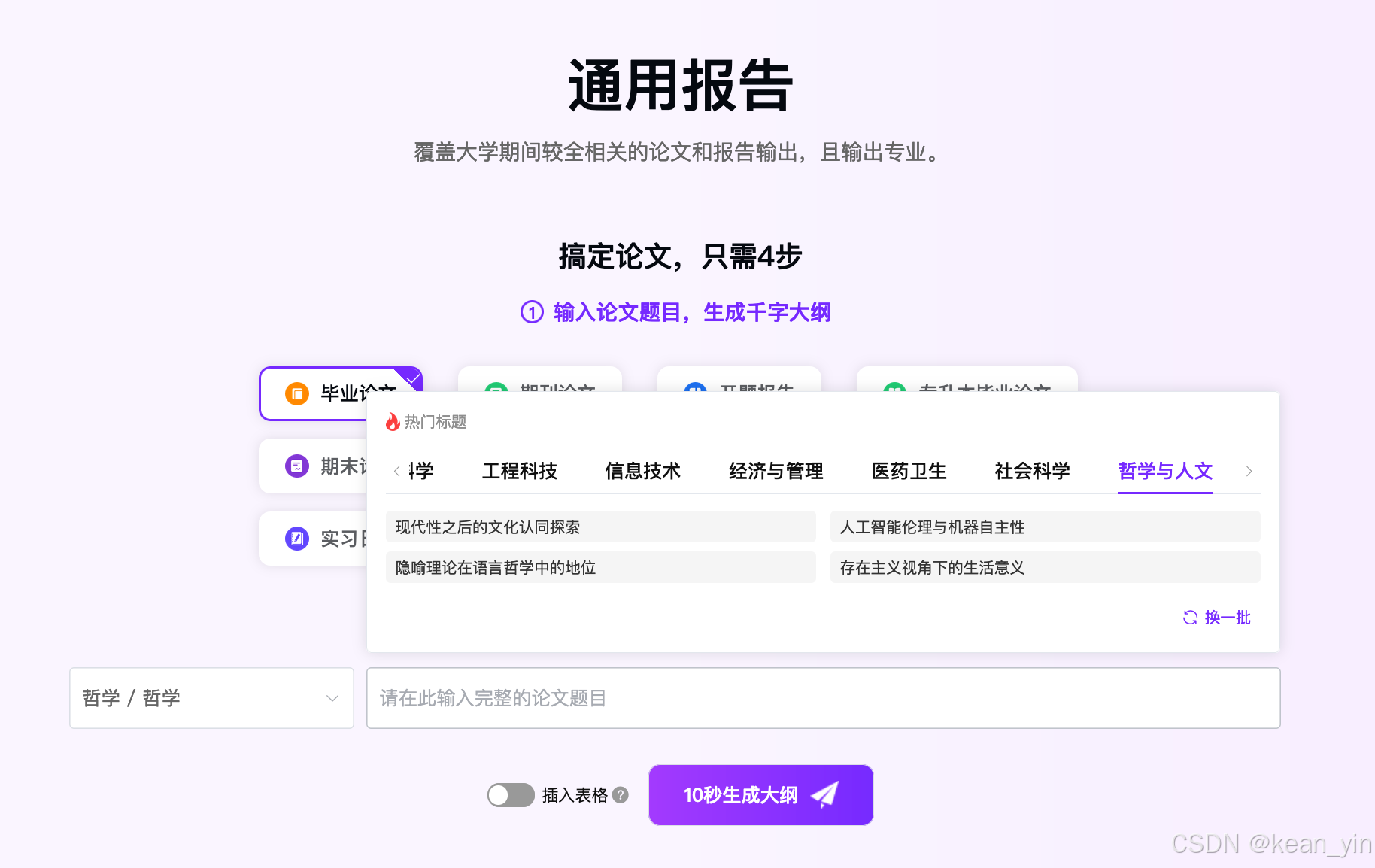
2.2.2 编辑和新增内容
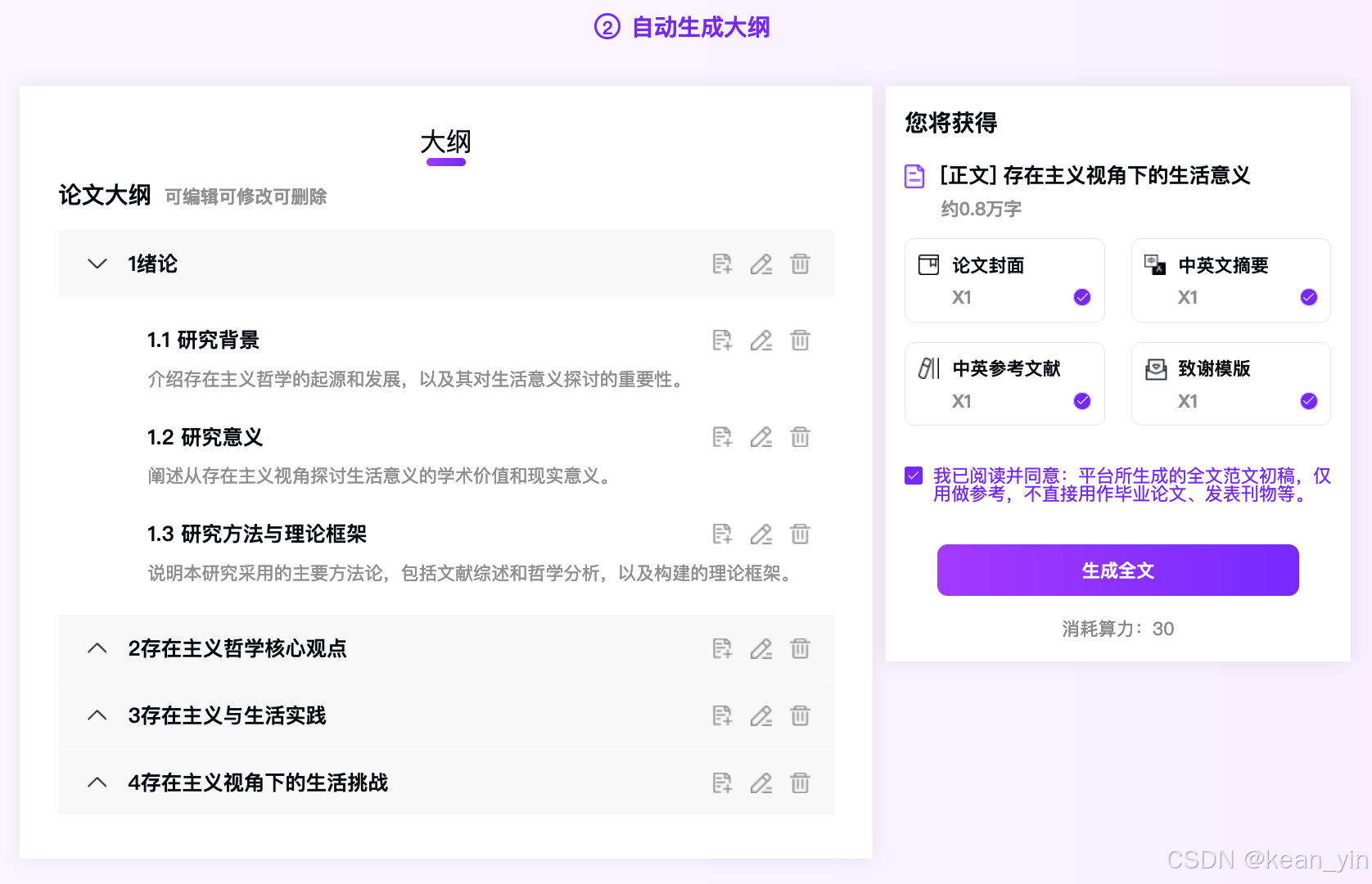
2.2.3 生成和下载
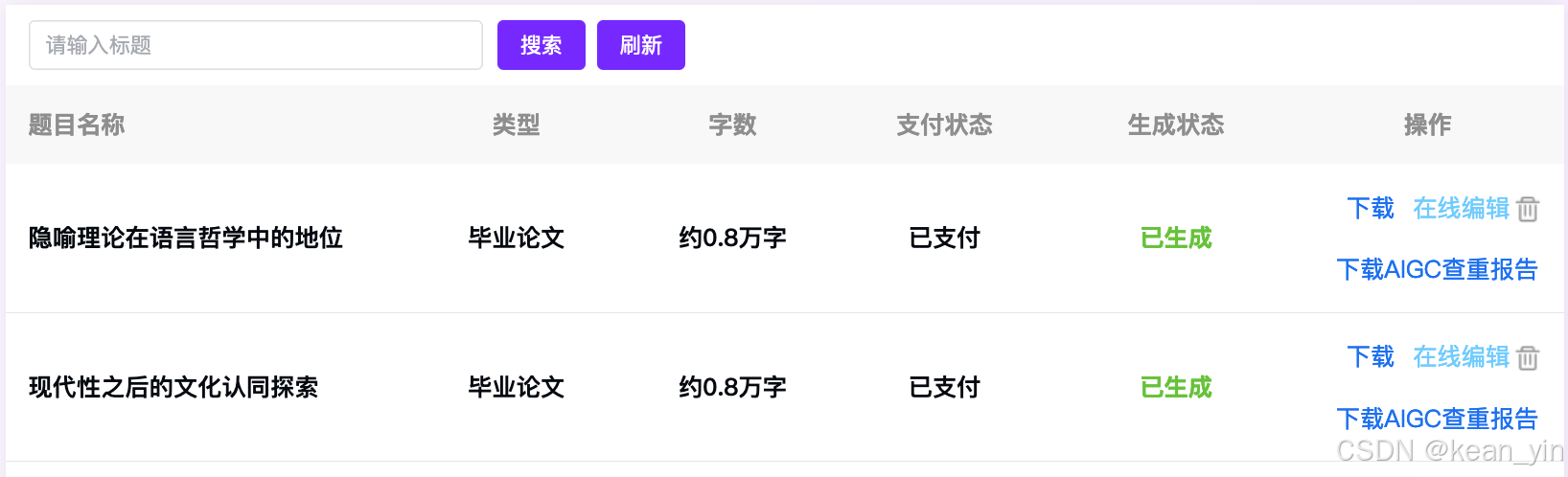
2.2.4 在线编辑

六 纪元


