Data·Stack
首页
门类
默认分类
大数据
JAVA
PYTHON
晋级之路-数据结构·算法
千变工作-BI
LangChain
大模型
埃利斯-踏足社会
咻咻
抖音热榜
关于
切换主题
登录
Data·Stack
首页
门类
默认分类
大数据
JAVA
PYTHON
晋级之路-数据结构·算法
千变工作-BI
LangChain
大模型
埃利斯-踏足社会
咻咻
抖音热榜
关于
遇事不决,可问春风
Kafka副本同步策略(ISR)
2024-01-18
446
0
Kafka
遇事不决,可问春风
Hadoop和Spark的联系
2023-12-29
150
0
Spark
Scala
图片加载失败
Flink中的多事件Join
2023-12-28
264
0
Flink
遇事不决,可问春风
字符串的最长公共前缀
2023-12-25
149
0
数据结构与算法
Java
遇事不决,可问春风
两两交换链表节点(链表相邻节点交换)
2023-12-25
161
0
数据结构与算法
Java
图片加载失败
面试-笔试题集锦
2023-10-16
190
0
Hive
数据仓库
Spark
Java
Hadoop
图片加载失败
二叉树的遍历
2023-10-12
132
0
数据结构与算法
图片加载失败
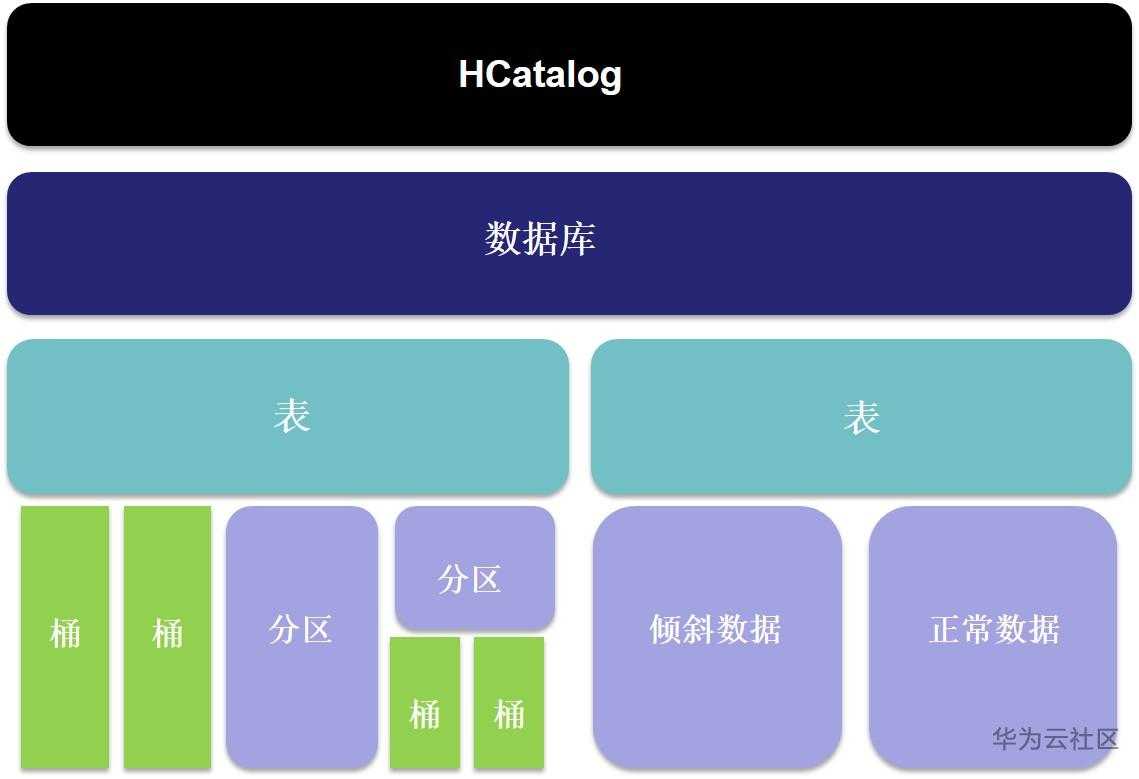
Hive-数据模型
2023-10-11
227
0
Hive
图片加载失败
hive基础-知识必备
2023-10-11
248
0
Hive
数据仓库
图片加载失败
Spark基础-基础必备
2023-10-09
167
0
Spark
1
...
4
5
6
7
小尹呀
互联网数据职场人一枚,企业级数据仓库0-1,智能体实践行业经验。
文章
64
分类
10
标签
16
热门文章
1
LangGraph 使用指南
2025-04-07
2
阿里巴巴通义千问聊天模型集成指南
2025-04-07
3
LangSmith 设置指南
2025-04-07
4
聊天模型比较指南
2025-04-07
5
(搜索智能体)LangChain 搜索与智能体集成技术总结
2025-04-07
随机视频
标签云
热点要闻
大模型框架
ETL
产品
图集
数据分析BI
数据结构与算法
chatGPT
Kafka
Flink
Spark
Java
Scala
Hadoop
数据仓库
Hive
数据栈赞助者
🍬
豆豆
10
1%
成为数据栈赞助商
每笔赞助都会化作数据栈能量 助力我们创作更多美好内容✨